Batch Size and Running Speed
Experiment Overview
This document covers experiments on batch_size and running_speed. Baseline: uni_5 (batch 2048, speed 160×).
Direction 1 — Larger batch: Increasing batch to 8192 (uni_6) worsened convergence and loss; RTX 5090 hit a performance ceiling.
Direction 2 — Smaller batch + faster speed: Reducing batch to 512 and speed to 512× (uni_7) improved convergence, loss, and GPU utilization. Follow-up runs uni_8 and uni_9 (even smaller batch, higher speed) reversed those gains: over-tuning hurt. Conclusion: a golden middle between batch_size and running_speed is needed; uni_7 (512/512) is in that range.
Direction 3 — Map cycle length: uni_11 and uni_12 kept the same batch/speed as uni_7 (512/512) but changed the map cycle. uni_11: 256 hock – 256 A01 — at 55 min uni_11 better Hock (60.69s vs 61.94s), uni_7 better A01; ambiguous. uni_12: 64 hock – 64 A01 — uni_12 converges faster on A01 (24.85s by 20 min vs uni_7 by 40 min), lower loss and better Q over 55 min; at 55 min uni_7 slightly better A01, Hock close. uni_12 clearly better than uni_11 on A01. Conclusion: 64–64 is recommended; prefer it over 4–4 and over 256–256.
Results
Important: Experiments had different durations (uni_5 ~160 min, uni_7 ~86 min, etc.), so comparing by “last value” is meaningless. All findings below are based on aligned time checkpoints from analyze_experiment_by_relative_time.py. With default --time-axis auto, those checkpoints are cumulative training hours when the scalar is logged (same idea as console Training hours); for these short single-session uni_* runs that is usually close to wall-clock minutes from the first TB event. If a run was restarted, use scripts/audit_tensorboard_training_timeline.py and see Experiments. Metrics are compared at the same checkpoints up to when the shortest run ends.
Data source: All numbers below are from scripts/analyze_experiment_by_relative_time.py (per-race tables for race times: Hock = long track ~55–70 s, A01 = short track ~24–25 s). Reproduce: python scripts/analyze_experiment_by_relative_time.py uni_5 uni_7 ... --interval 5 (--logdir <path> if needed).
Key Findings (by relative time):
Larger batch (uni_6): At 160 min — worse best times (Hock 66.94s vs 58.70s for uni_5; A01 24.77s vs 24.56s), loss ~10× higher (2979 vs 301), GPU % no gain (~52% vs ~54%). Do not go above 2048.
Smaller batch + faster speed (uni_7): uni_7 reaches good times faster (at 60 min Hock 60.58s vs uni_5 69.27s; at 85 min Hock 58.76s vs 65.04s; A01 tie 24.58s). Loss much lower, Q better, GPU ~78% vs ~53%. Best trade-off.
Over-tuning (uni_8, uni_9): At 70 min — uni_7 best: Hock 60.58s vs 74.24s / 80.23s; A01 24.63s vs 25.18s / 25.25s. uni_8/9 have higher GPU % but worse policies.
Fewer collectors (uni_10, gpu_collectors_count=4): At 85 min uni_7 ahead: Hock 58.76s vs 62.11s, A01 24.58s vs 24.72s. Main point — throughput and GPU %: ~59% vs ~79%. For maximum training speed, 8 collectors are better.
Map cycle 256 hock – 256 A01 (uni_11 vs uni_7): At 55 min — uni_11 better Hock (60.69s vs 61.94s), uni_7 better A01 (24.72s vs 25.08s). Loss and Q close (uni_7 113, uni_11 106; Q -1.24 vs -1.10). GPU % uni_7 ~79% vs uni_11 ~70%. Interpretation ambiguous.
Map cycle 64 hock – 64 A01 (uni_12 vs uni_7, uni_11): uni_12 converges faster on A01 — 24.85s by 20 min (uni_7 24.95s only by 40 min). At 55 min: Hock uni_7 61.94s, uni_12 61.68s (close); A01 uni_7 24.72s, uni_12 24.85s (uni_7 slightly better). Loss and Q better for uni_12 (102.8 vs 113, -0.71 vs -1.24). Versus uni_11: uni_12 better on A01 and convergence. Conclusion: 64–64 is recommended: faster A01 convergence and better loss/Q than uni_7 over 55 min; clearly better than 256–256 on A01.
Run Analysis
All runs use the same hardware (RTX 5090). uni_5–uni_9: 8 collectors; uni_10, uni_11, uni_12: 8 collectors. TensorBoard logs: tensorboard\uni_<N>. Durations (relative time): uni_5 ~160 min, uni_6 ~165 min, uni_7 ~86 min, uni_8 ~76 min, uni_9 ~194 min, uni_10 ~71 min, uni_11 ~55 min, uni_12 ~55 min.
uni_5: Baseline — batch_size = 2048, running_speed = 160, ~160 min
uni_6: Larger batch 8192, speed 160, ~165 min — by relative time worse Hock and loss
uni_6_2: Continuation of uni_6 (same config)
uni_7: Smaller batch 512, speed 512, 8 collectors, map cycle 4 hock – 4 A01 (+ 1 eval A01 at end), ~86 min — best trade-off by relative time
uni_8: Further smaller batch + higher speed, ~76 min — worse than uni_7 on times and Q on common window
uni_9: Extreme (e.g. batch 64, speed 1024), ~194 min — worse than uni_7 on common window up to 70 min
uni_10: Same as uni_7 (batch 512, speed 512) but gpu_collectors_count = 4, ~71 min — sometimes slightly faster on time early on, by 70 min slightly worse; throughput and GPU % lower (~59% vs ~79%).
uni_11: Same as uni_7 (batch 512, speed 512, 8 collectors) but map cycle 256 hock – 256 A01 (+ 1 eval A01 at end), ~55 min — by relative time slightly more events than uni_7; metrics close, uni_7 slightly better on times and GPU % over common window up to 55 min.
uni_12: Same as uni_7 (batch 512, speed 512, 8 collectors) but map cycle 64 hock – 64 A01 (+ 1 eval A01 at end), ~55 min — by relative time faster convergence, equal or better A01 and loss/Q than uni_7 over 55 min; clearly better than uni_11 (256–256). Recommended map cycle length for this setup.
To reproduce metrics by relative time: python scripts/analyze_experiment_by_relative_time.py uni_5 uni_7 --interval 5 (or uni_5 uni_6 uni_7 uni_10 uni_11 uni_12 for all runs; --logdir "<path_to_tensorboard>" if not from project root). For last-value comparison: python scripts/analyze_experiment.py uni_5 uni_6 uni_7 ....
Analysis methodology
The script analyze_experiment_by_relative_time.py supports two or more runs (e.g. uni_5 uni_6 uni_7 uni_10 uni_11 uni_12). Default auto time axis uses cumulative training hours when logged; with --time-axis wall_minutes, checkpoints are 5, 10, 15, … wall minutes up to the shortest run.
Race times (preferred): Uses per-race events
Race/eval_race_time_*andRace/explo_race_time_*. For each run, one run-wide t0 (min wall_time across race tags) is used so “5 min” is the same moment for all tags. At each checkpoint T min: best = min of race times with rel_min ≤ T, mean, std (stability), best_fin (best among finished only), finish rate, first finish (minute). This gives more dynamics and stability info than scalar metrics alone.Scalar metrics:
alltime_min_ms_{map},Training/loss,RL/avg_Q_*,Performance/learner_percentage_trainingat each checkpoint (best so far for race times, last value for loss/Q/GPU).Race times in the script output use per-race tables (
Race/eval_race_time_*,Race/explo_race_time_*); Hock is the long track (~55–70 s), A01 the short track (~24–25 s).
Detailed TensorBoard Metrics Analysis
Metrics below are from TensorBoard logs (tensorboard\uni_<N>). Baseline is uni_5 (2048 batch, 160 speed). The figures below show comparison plots (one metric per graph, runs as lines, by relative time) for the main comparisons.
Methodology — Aligned time checkpoints: Experiments had different durations (see Run Analysis), so comparing by “last value” is invalid. Default auto uses cumulative training hours; for these short uni_* runs the minute labels below still match historical checkpoints (≈ wall time). Comparison runs only until the shortest run ends. Race times: per-race events or alltime_min_ms_*. Loss / Q / GPU %: last value at that checkpoint. Regenerate: python scripts/analyze_experiment_by_relative_time.py <runs> (--interval-training-hours 0.0833 ≈ 5 min, or --time-axis wall_minutes --interval 5). See Experiments.
Key metrics (aligned with TensorBoard Metrics Reference): Per-race: Race/eval_race_time_*, Race/explo_race_time_* (best/mean/std, finish rate). Scalars: alltime_min_ms_{map}, Training/loss, RL/avg_Q_*, Performance/learner_percentage_training. Also: Performance/transitions_learned_per_second, Gradients/norm_before_clip_max. For interpretation see that file.
Larger batch: uni_5 vs uni_6 (relative time, common window up to 160 min)
Hock (per-race explo): at 160 min — uni_5 58.70s, uni_6 66.94s → uni_6 worse.
A01 (per-race eval): at 160 min — uni_5 24.56s, uni_6 24.77s → uni_6 worse.
Training/loss: at 160 min — uni_5 301, uni_6 2979 → ~10× higher in uni_6.
RL/avg_Q_trained_A01: at 160 min — uni_5 -0.79, uni_6 -1.23 → uni_6 more negative.
Performance/learner_percentage_training: ~53% uni_5, ~52% uni_6 → no gain; performance ceiling.
Smaller batch + faster speed: uni_5 vs uni_7 (relative time, common window up to 85 min)
Hock (per-race explo): at 60 min — uni_5 69.27s, uni_7 60.58s; at 85 min — uni_5 65.04s, uni_7 58.76s → uni_7 better; reaches good Hock earlier.
A01 (per-race eval): at 85 min — uni_5 24.58s, uni_7 24.58s (tie).
Training/loss: at 85 min — uni_5 355, uni_7 77.72 → much lower in uni_7.
RL/avg_Q_trained_A01: at 85 min — uni_5 -0.60, uni_7 -0.41 → better in uni_7.
Performance/learner_percentage_training: ~53% uni_5, ~78% uni_7 → +25% for uni_7.
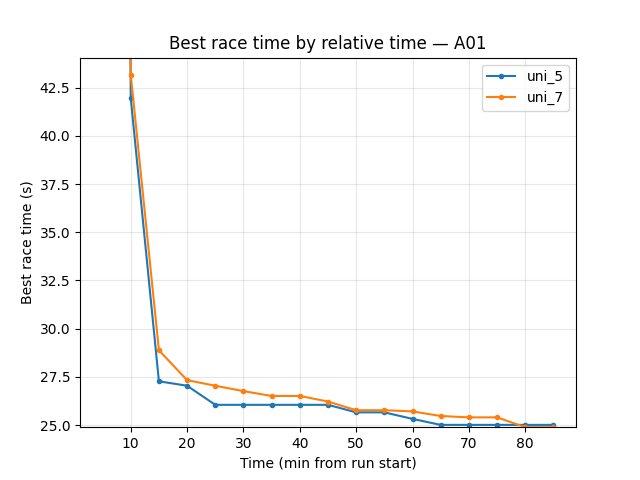
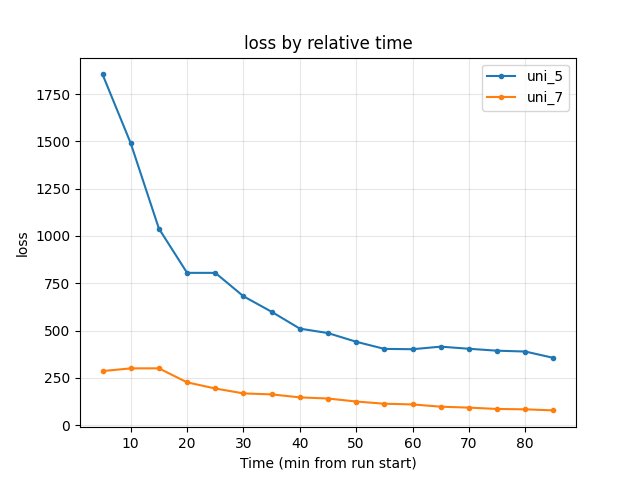
Over-tuning: uni_7 vs uni_8 vs uni_9 (relative time, common window up to 70 min)
Hock (per-race explo): at 70 min — uni_7 60.58s, uni_8 74.24s, uni_9 80.23s → uni_7 better.
A01 (per-race eval): at 70 min — uni_7 24.63s, uni_8 25.18s, uni_9 25.25s → uni_7 better.
Training/loss: at 70 min — uni_7 92.4, uni_8 53.4, uni_9 45.4; uni_8/9 have lower raw loss but race times and Q worse ⇒ loss alone misleading.
RL/avg_Q_trained_A01: at 70 min — uni_7 -0.85, uni_8 -1.37, uni_9 -2.31 → uni_7 better.
Performance/learner_percentage_training: uni_7 ~79%, uni_8 ~80%, uni_9 ~82% — higher % does not yield better policies.
uni_7 vs uni_10 (gpu_collectors_count, relative time, common window up to 85 min)
uni_10 — same batch_size 512 and running_speed 512 as uni_7, but gpu_collectors_count = 4 instead of 8.
Hock (per-race explo): at 70 min — uni_7 60.58s, uni_10 62.11s; at 85 min — uni_7 58.76s, uni_10 62.11s → uni_7 better by end of common window.
A01 (per-race eval): at 85 min — uni_7 24.58s, uni_10 24.72s → uni_7 slightly better.
Training/loss: at 85 min — uni_7 77.72, uni_10 100.69 — close over the window.
RL/avg_Q_trained_A01: at 85 min — uni_7 -0.41, uni_10 -0.65 — close.
Performance/learner_percentage_training: uni_7 ~79%, uni_10 ~59% → throughput and GPU % substantially lower for uni_10.
Conclusion for uni_10: By relative time uni_7 is ahead on Hock and A01 by end of common window. Main difference — fewer ops per unit time and lower GPU %; for maximum training speed, 8 collectors are better.
uni_7 vs uni_11 (map cycle 4–4 vs 256–256, relative time, common window up to 55 min)
uni_11 — same batch_size 512 and running_speed 512 as uni_7, but map cycle 256 hock – 256 A01 (+ 1 eval on A01 at the end) instead of 4 hock – 4 A01. uni_11 ~55 min; uni_7 ~86 min.
Hock (per-race explo): at 15 min — uni_7 89.48s, uni_11 64.58s (uni_11 faster early); at 55 min — uni_7 61.94s, uni_11 60.69s → uni_11 slightly better Hock at end of window.
A01 (per-race eval): at 55 min — uni_7 24.72s, uni_11 25.08s → uni_7 better on A01.
Training/loss: at 55 min — uni_7 113.0, uni_11 106.0 — close.
RL/avg_Q_trained_A01: at 55 min — uni_7 -1.24, uni_11 -1.10 — close.
Performance/learner_percentage_training: uni_7 ~79% vs uni_11 ~70% → uni_7 higher GPU %.
Conclusion for uni_11: At 55 min uni_11 has slightly better Hock (60.69s vs 61.94s), uni_7 better A01 (24.72s vs 25.08s). Interpretation ambiguous — 256–256 is not clearly better or worse; more data or longer runs would help.
uni_7 vs uni_12 (map cycle 4–4 vs 64–64, relative time, common window up to 55 min)
uni_12 — same batch_size 512 and running_speed 512 as uni_7, but map cycle 64 hock – 64 A01 (+ 1 eval on A01 at the end) instead of 4 hock – 4 A01. uni_12 ~55 min; uni_7 ~86 min.
Hock (per-race explo): at 55 min — uni_7 61.94s, uni_12 61.68s → close (uni_12 slightly better). uni_12 gets first Hock finish later (19.4 min vs 11.1 min for uni_7) but reaches 61.68s by 55 min.
A01 (per-race eval): uni_12 converges faster — 24.85s by 20 min (uni_7 24.95s only by 40 min). At 55 min — uni_7 24.72s, uni_12 24.85s → uni_7 slightly better at end of window; uni_12 much faster to good A01.
Training/loss: at 55 min — uni_7 113.0, uni_12 102.8 → uni_12 lower (better).
RL/avg_Q_trained_A01: at 55 min — uni_7 -1.24, uni_12 -0.71 → uni_12 better (less negative); at 20 min uni_12 -0.83 vs uni_7 -1.44.
Performance/learner_percentage_training: uni_7 ~79% vs uni_12 ~72% → uni_7 higher GPU %; uni_12 has faster A01 convergence and better loss/Q.
Conclusion for uni_12: Over 55 min uni_12 converges faster on A01 (24.85s by 20 min vs uni_7 by 40 min) and has lower loss and better Q. At 55 min uni_7 is slightly better on A01 (24.72s vs 24.85s) and Hock is close (61.94s vs 61.68s). Versus uni_11 (256–256), uni_12 is clearly better on A01 and convergence. Recommendation: Prefer 64 hock – 64 A01 over 4–4 and over 256–256 for this setup.
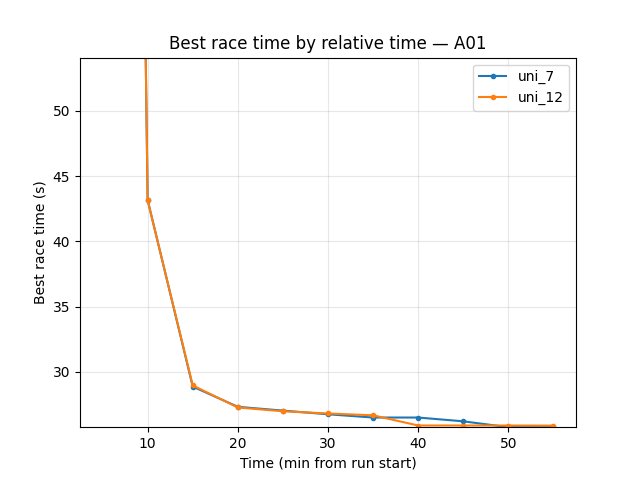
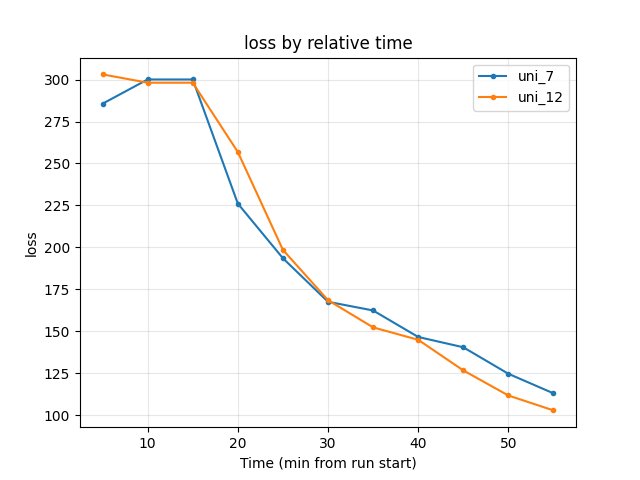
Other metrics (from TensorBoard Metrics Reference)
When comparing batch/speed setups, also check in TensorBoard or via scripts/extract_tensorboard_data.py:
Performance/transitions_learned_per_second — training throughput; higher is better; reflects efficiency of the pipeline.
Gradients/norm_before_clip_max — training stability; spikes >100 indicate gradient explosion; should stay relatively stable. Compare runs to ensure no setup introduces instability.
Full interpretation and “what to watch for” for all metrics: TensorBoard Metrics Reference.
Configuration Changes
Training (training section): batch_size was varied (2048 baseline, 8192 in uni_6, 512 in uni_7, smaller in uni_8/uni_9). Recommended: 512.
Performance (performance section): running_speed was varied (160 baseline, 512 in uni_7, higher in uni_8/uni_9). Recommended: 512. gpu_collectors_count: uni_10 used 4 with same 512/512 — throughput and GPU % drop; for maximum training speed keep 8.
Map cycle (map_cycle section): uni_7 used 4 hock – 4 A01 (+ 1 eval on A01 at the end); uni_11 256 hock – 256 A01; uni_12 64 hock – 64 A01 (+ 1 eval on A01 at the end). Same batch/speed as uni_7. By relative time uni_12 (64–64) converges faster and gives equal or better A01, loss, and Q over the common 55 min window than uni_7; clearly better than uni_11. Recommended: 64–64.
# Recommended (uni_7-style)
batch_size = 512 # not 2048, not 8192, not 64
running_speed = 512 # not 160, not 1024
gpu_collectors_count = 8 # 4 (uni_10) yields fewer ops/sec and lower GPU %
Hardware
GPU: RTX 5090
Parallel instances: 8 collectors (uni_5–uni_9, uni_11, uni_12); uni_10 used 4 — less throughput
System: Same across all runs
Conclusions
Conclusions are given by aligned time checkpoints (default script: cumulative training hours; here, short runs ⇒ close to wall minutes); comparing by “last value” when runs have different duration is invalid.
Larger batch (8192) hurts: On the common window by relative time — worse best times, ~10× higher loss, GPU % no gain (~52%). Keep batch ≤ 2048 or use 512 for the “small batch + fast speed” regime.
Smaller batch (512) + faster speed (512×) helps: At the same minutes from start uni_7 reaches good times faster, much lower loss, better Q, ~78% GPU. Best observed trade-off.
Over-tuning (smaller batch + higher speed) hurts again: On the common window up to 70 min uni_8/uni_9 do not reach uni_7-level times and Q. Golden middle — uni_7 (512/512); extremes (e.g. 64/1024) degrade quality.
Trade-offs: Smaller batches need more frequent sync; very high speed can affect physics; going beyond the sweet spot (batch/speed) degrades performance.
gpu_collectors_count (uni_10): By relative time quality is close to uni_7; uni_10 sometimes slightly faster early on. Main point — drop in throughput and GPU % (~59% vs ~79%); for maximum training speed by wall clock, 8 collectors are better.
Map cycle length (uni_11, uni_12): 256–256 (uni_11): At 55 min uni_11 better Hock (60.69s vs 61.94s), uni_7 better A01 (24.72s vs 25.08s); ambiguous. 64–64 (uni_12): uni_12 converges faster on A01 (24.85s by 20 min vs uni_7 by 40 min), lower loss and better Q over 55 min; at 55 min uni_7 slightly better A01 (24.72s vs 24.85s), Hock close (61.94s vs 61.68s). uni_12 clearly better than uni_11 on A01. Recommendation: Use 64 hock – 64 A01 over 4–4 and over 256–256.
Recommendations
Use batch_size = 512 and running_speed = 512 as the default “golden middle” for this setup (IQN, RTX 5090).
Use gpu_collectors_count = 8 for maximum throughput; 4 collectors (uni_10) reduce ops per unit time and GPU share on training (~59% vs ~78%).
Avoid very small batch (e.g. 64) with very high speed (e.g. 1024); it slows training and convergence.
Do not increase batch beyond 2048 (or 512 if using the fast-speed regime) without evidence of benefit.
Monitor training loss, map times, and Q-values; GPU % alone is not sufficient.
Tune batch_size and running_speed together; uni_7 (512/512) is a proven working point.
Map cycle: Prefer 64 hock – 64 A01 (uni_12): by relative time it converges faster on A01 and has lower loss and better Q than 4–4 (uni_7) over 55 min, and is clearly better than 256–256 (uni_11) on A01. Use 64–64 as the default map cycle for this setup.
When to change:
Larger batches (1024–2048): if GPU memory or sync overhead is the bottleneck.
Slower speed (160–200): if physics or stability is critical.
Keep 512/512 unless you have a clear reason to move away.
Analysis Tools:
Activate venv (Windows):
.\.venv\Scripts\activateBy relative time (compare at the same minutes from start; 2+ runs):
python scripts/analyze_experiment_by_relative_time.py uni_5 uni_7 --interval 5orpython scripts/analyze_experiment_by_relative_time.py uni_5 uni_6 uni_7 uni_10 uni_11 uni_12 --interval 5(--logdir "<path>"if not from project root). Output: per-race tables (best/mean/std, finish rate, first finish) then scalar metrics.By “last value” (less meaningful when durations differ):
python scripts/analyze_experiment.py uni_5 uni_6 uni_7 ...scripts/extract_tensorboard_data.py— selective metrics (Gradients/norm_before_clip_max,Performance/transitions_learned_per_second, etc.).Key metrics (see TensorBoard Metrics Reference): Per-race
Race/eval_race_time_*,Race/explo_race_time_*; scalarsTraining/loss,alltime_min_ms_{map},RL/avg_Q_*,Performance/learner_percentage_training,Gradients/norm_before_clip_max(stability).