BC pretrain: training length & early stop (Level 1)
Experiment Overview
This experiment compares two BC (behavioral cloning) pretrain runs to answer: how long to train, and whether early stopping is beneficial. Both runs use the same data and architecture (backbone mode, encoder init from Level 0 visual), but:
v1: Stopped at 25 epochs (early stopping enabled in config, or 25-epoch cap). Lower final val_loss (1.038) at stop.
v1.1: No early stopping, lr=0.0005, full 50 epochs. Slightly higher final val_loss (1.119); train_acc a bit higher (0.699 vs 0.696).
Goal: understand if we can use early stopping to save time without hurting downstream RL, and how per-action accuracy (e.g. left, right, accel, brake) evolves. When using multi-offset BC (bc_time_offsets_ms with several values), per-offset accuracy is logged (e.g. train_acc_offset_ms_-10, val_acc_offset_ms_0, val_acc_offset_ms_10) in TensorBoard and metrics.csv for analysis in doc/exp.
A second experiment (v1.1 vs v1.2) compares image normalization: v1.2 uses IQN-style normalization (x - 0.5) / 0.5 at BC input (cache is [0,1]), while v1.1 uses default [0, 1]. Both use the same visual backbone (Level 0 vis/v1) trained without IQN normalization, so v1.2 tests whether normalizing inputs at BC time improves validation loss and generalization despite the backbone having been pretrained on [0,1].
A third experiment (full IQN-aligned chain v2) trains a new visual backbone with IQN normalization (vis v2), then runs BC with that backbone and IQN normalization (BC v2). This removes the distribution mismatch: both Level 0 and Level 1 use (x - 0.5) / 0.5. Comparison v1.2 vs v2 shows whether full alignment (vis + BC both with IQN norm) improves over “BC-only” IQN norm (v1.2 with vis/v1).
Why IQN normalization exists (RL) and why pretrain should match it
In the RL pipeline, image inputs to the IQN network are always normalized as (x - 128) / 128: raw pixels are uint8 [0, 255], and the first step in the learner (e.g. in buffer_utilities.py when building batches and in agents/iqn.py in the inference path) is (img - 128) / 128. So the network sees inputs in roughly [-1, 1] (zero-centered, bounded).
Why this is used in IQN:
Zero-centering: Input mean ~0 (mid-gray 128 -> 0). The first layer does not need to compensate for a constant positive bias; gradients and learning are more stable.
Bounded symmetric range: Many architectures and initializations assume inputs in a bounded range; [-1, 1] is standard and avoids saturation at 0 or 255.
Why use the same convention in pretrain/BC:
When we transfer a pretrained encoder into IQN, the encoder is placed inside the same forward path: it will receive (x - 128) / 128 at RL time. If we trained the encoder on [0, 1] (e.g. v1.1: cache /255, no extra transform), then at transfer the encoder would see [-1, 1] — a distribution shift. The network was optimized for one input distribution and is then fed another, which hurts generalization (and can hurt RL sample efficiency). If we train BC (and optionally the visual backbone) with IQN-style normalization, we use (x - 0.5) / 0.5 on the [0, 1] cache, which maps to the same [-1, 1] range as (x - 128) / 128 for x in [0, 255]. So at transfer there is no distribution shift: the encoder sees the same input distribution it was trained on.
How the experiments align with this:
v1.1 (no IQN norm): Encoder and BC head trained on [0, 1]. At transfer to IQN they would see [-1, 1]. Shift -> worse generalization (val_loss 1.12, overfitting). Raw val_acc can still be high (0.625) because we are fitting the [0,1] training distribution well.
v1.2 (IQN norm at BC): Backbone gets fine-tuned on (x-0.5)/0.5 = [-1, 1] during BC; at transfer IQN feeds [-1, 1]. No shift -> better val_loss (0.95), better main_actions at best epoch.
v2 (full chain): Backbone and BC both trained on [-1, 1]. At transfer, same. No shift -> similar val_loss to v1.2; trade-offs are in which actions (e.g. coast) are predicted slightly better.
So the normalization in RL is there for training stability and a fixed input convention; using the same convention in pretrain removes distribution shift at transfer and matches the observed better generalization (v1.2/v2 vs v1.1).
Results
Important: v1 has 25 epochs (0–24), v1.1 has 50 epochs (0–49). Comparisons below are by epoch over the common window (0–24). At epoch 24, v1 is at its final checkpoint; v1.1 continues to epoch 49.
Key findings
Val loss: At epoch 24, v1 val_loss = 1.038, v1.1 val_loss = 1.045. v1 (early stop) has slightly better val_loss at the same epoch. By epoch 49, v1.1 val_loss = 1.119 (worse than v1 at 24), so training past ~25 epochs increases val_loss (overfitting).
Overall accuracy: At epoch 24, v1 val_acc ≈ 0.624, v1.1 ≈ 0.619. Final v1.1 (epoch 49) val_acc ≈ 0.625 — almost no gain from extra epochs.
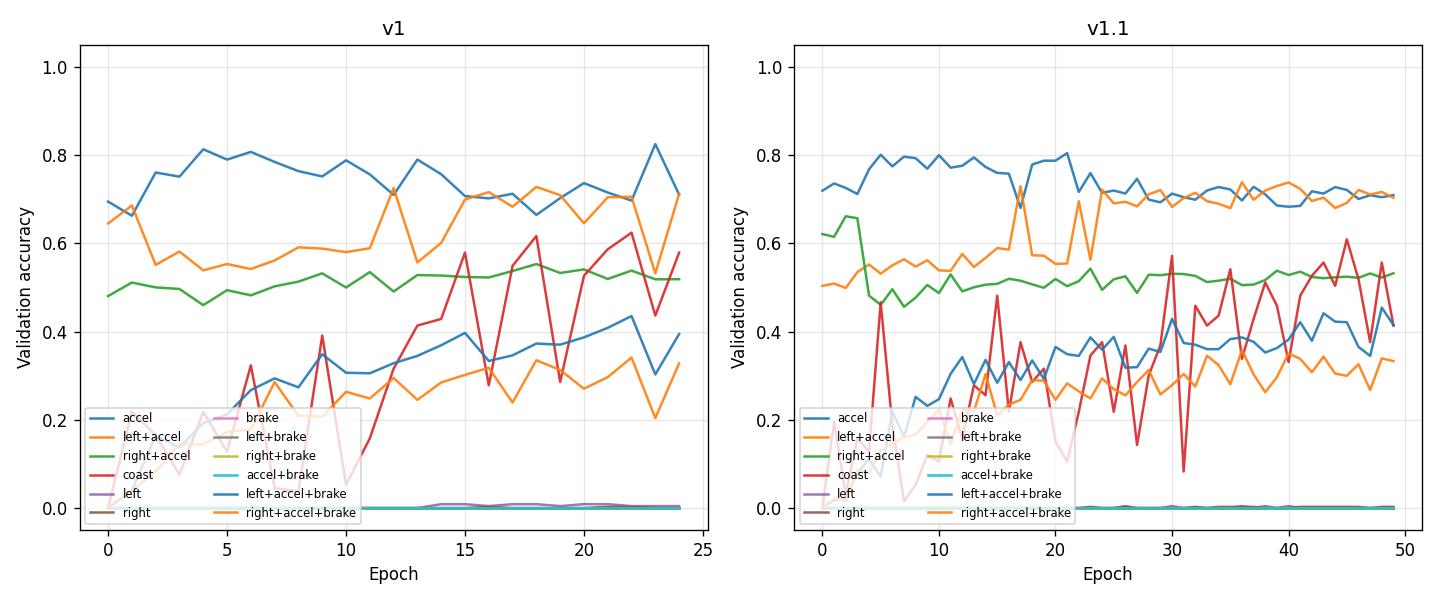
Per-action accuracy (validation): Main predictive power is in accel, left+accel, right+accel, coast, left+accel+brake, right+accel+brake. Actions left, right, brake, left+brake, right+brake, accel+brake have near-zero or zero samples in validation, so val_acc_class_* is 0 or very small.
Combined (loss + per-action accuracy): The script reports best epoch by val_loss and at that epoch: val_loss, val_acc, and main_actions_val_acc (mean over the six actions above). For v1 the minimum val_loss is at epoch 14 (val_loss 0.997, main_actions_val_acc 0.49); for v1.1 at epoch 11 (val_loss 0.994, main_actions_val_acc 0.42). At later epochs (e.g. 24), overall val_acc and per-action accuracies are higher (e.g. v1 at 24: val_acc 0.62, accel/left+accel ~0.71, coast ~0.58), while val_loss is slightly higher. So: stopping at min val_loss gives the lowest loss but lower per-action accuracy; stopping around 20–25 epochs gives a better trade-off (good loss and higher accuracy on main actions). Prefer early stopping with patience 5–10 so the run stops after val_loss flattens but before overfitting, typically around 20–25 epochs.
Conclusion: Early stopping around 20–25 epochs is sufficient; training to 50 epochs (v1.1) does not improve val loss or val accuracy and leads to overfitting. Use early stopping (e.g. on val_loss with patience 5–10) to save time. When comparing runs, consider both val_loss and per-action accuracy (or main_actions_val_acc).
Normalization (v1.1 vs v1.2):
Val loss: v1.2 (IQN normalization) achieves substantially lower final val_loss (0.949 vs 1.119) and better best-epoch val_loss (0.941 at epoch 38 vs 0.994 at epoch 11). Normalization helps generalization (lower validation loss).
Val accuracy: At last epoch, overall val_acc is slightly lower in v1.2 (0.618 vs 0.625); at best epoch by val_loss, v1.2 has higher main_actions_val_acc (0.52 vs 0.42). So loss improves clearly; accuracy is similar or better at the best checkpoint.
Per-action: v1.2 improves accel (0.80 vs 0.71) and coast (0.45 vs 0.41); left+accel and right+accel+brake are slightly lower at epoch 49. The main takeaway is better val_loss with IQN normalization.
Caveat: Both runs use a visual backbone (vis/v1) trained without IQN normalization. So there’s a distribution mismatch: the backbone saw [0,1] during Level 0 pretrain; in v1.2 the BC input is transformed to (x-0.5)/0.5 before the backbone. Despite this mismatch, IQN normalization at BC time helps: lower val_loss and better best-epoch metrics. For full alignment, the next step would be to pretrain the visual backbone with IQN normalization as well, then run BC with IQN normalization.
Full chain comparison (v1.2 vs v2) — which is best for action prediction accuracy?
Overall: v1.2 and v2 are very close (val_loss 0.948–0.949, val_acc 0.616–0.618). At best epoch by val_loss, v1.2 has higher main_actions_val_acc (0.517 vs 0.507), so v1.2 is marginally better for aggregate action prediction accuracy.
Per-action: v2 is clearly better for coast (0.64 vs 0.45); v1.2 is slightly better on accel, left+accel+brake. So: for best overall action accuracy use v1.2; for best coast use v2.
Three-way comparison (v1.1 vs v1.2 vs v2) — action prediction accuracy:
Overall val_acc (last epoch): v1.1 0.625 > v1.2 0.618 > v2 0.616. v1.1 has the highest raw val_acc at epoch 49.
Val_loss (generalization): v1.2 and v2 ~0.948 (best); v1.1 1.119 (worst). So v1.1 overfits more.
Best epoch by val_loss: v1.1 best at epoch 11 (val_loss 0.994, main_actions_val_acc 0.42); v1.2 and v2 best at epoch 38 (main_actions_val_acc 0.517 and 0.507). main_actions_val_acc (mean over accel, left+accel, right+accel, coast, left+accel+brake, right+accel+brake) is best for v1.2 at the best checkpoint.
Per-action (epoch 49): v1.1 leads on left+accel (0.70), right+accel (0.53), right+accel+brake (0.33); v1.2 leads on accel (0.80), left+accel+brake (0.42); v2 leads on coast (0.64). v1.1 has lowest coast (0.41).
Summary: For highest overall val_acc at the end of training, v1.1 wins (0.625) but has worst val_loss. For best balance of generalization and main-actions accuracy (best epoch), v1.2 is best. For best coast prediction, v2. Reproduce with:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1.1 output/ptretrain/bc/v1.2 output/ptretrain/bc/v2 --interval 5.
Run Analysis
v1: BC pretrain from
output/ptretrain/vis/v1/encoder.pt, bc_mode=backbone, 25 epochs (stopped early or 25-epoch config). Val_loss final 1.038, val_acc 0.624. CSV:output/ptretrain/bc/v1/csv/metrics.csv(orcsv/version_0/metrics.csv).v1.1: Same encoder init and bc_mode, no early stopping, lr=0.0005, 50 epochs, image_normalization default [0,1]. Val_loss final 1.119, val_acc 0.625. CSV:
output/ptretrain/bc/v1.1/csv/metrics.csv.v1.2: Same as v1.1 (encoder from vis/v1, 50 epochs, no early stopping) but image_normalization: “iqn”
(x - 0.5) / 0.5(cache [0,1]). Val_loss final 0.949, val_acc 0.618. CSV:output/ptretrain/bc/v1.2/csv/metrics.csv.v2: Level 0 vis v2 (IQN norm, cache v0): 50 epochs, val_loss 0.207, encoder
output/ptretrain/vis/v2/encoder.pt. Level 1 BC v2: encoder from vis/v2, IQN norm, cache v0; 50 epochs; val_loss 0.948, val_acc 0.616. CSV:output/ptretrain/bc/v2/csv/metrics.csv.v2_next_tick: Same as v2 but bc_target: next_tick (predict action at next timestep). Config:
config_files/pretrain/bc/pretrain_config_bc_v2_next_tick.yaml. Run:python scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v2_next_tick.yaml.v2_multi_offset: Same base as v2_next_tick; bc_time_offsets_ms: [-10, 0, 10, 100] and bc_offset_weights: [0.2, 1.0, 0.5, 0.3] (four heads: past 10 ms, current, +10 ms, +100 ms). Config:
config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset.yaml. Run:python scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset.yaml. CSV and TensorBoard include per-offset accuracy (e.g.val_acc_offset_ms_-10,val_acc_offset_ms_0,val_acc_offset_ms_10,val_acc_offset_ms_100) for doc/exp.v2_multi_offset_ahead: Same as v2_multi_offset but use_actions_head: true (vis backbone + IQN A_head–style MLP heads only; no full IQN, no float head). Config:
config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead.yaml. Run:.\.venv\Scripts\python.exe scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead.yaml. Savesactions_head.pt(offset 0) for RL merge. See “Experiment: vis backbone + a_head only (v2_multi_offset_ahead vs v2_multi_offset)” for comparison.v2_multi_offset_ahead_tuned: Same as v2_multi_offset_ahead with tuned hyperparameters:
lr: 0.0002,weight_decay: 0.01(AdamW),early_stopping: true,patience: 10. Config:config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead_tuned.yaml. Improves val_acc and per-offset accuracy vs untuned ahead; stops around epoch 26. See “Experiment: vis backbone + a_head only” for comparison.v2_multi_offset_ahead_reg: Same as v2_multi_offset_ahead with reg-only tuning, no early stop:
lr: 0.0001,weight_decay: 0.02,early_stopping: false, full 50 epochs. Config:config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead_reg.yaml. Reaches val_acc 0.592 at epoch 49, best val_loss at epoch 35; per-offset ~0.597–0.598. Use when you want full 50 epochs without early stopping.v2_multi_offset_ahead_dropout: Same as v2_multi_offset_ahead_reg + dropout: 0.2 on features before action head. Config:
config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead_dropout.yaml. Best A_head variant so far: val_acc 0.595, val_loss 1.989 (epoch 49); per-offset 0.603 / 0.600 / 0.600 / 0.578. Use for RL merge when you want best val without early stop.v2_multi_offset_ahead_dropout_inner: Same as v2_multi_offset_ahead_dropout + action_head_dropout: 0.1 (dropout between the two Linear layers of A_head). Config:
config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead_dropout_inner.yaml. Best A_head run: val_acc 0.597, val_loss 1.971; per-offset 0.605 / 0.603 / 0.602 / 0.579; main_actions_val_acc 0.476, coast 0.374. Recommended for RL merge.v3: BC on maps/img (100 FPS), cache v1, use_full_iqn: true, use_floats: false (run without float state inputs; config file may have use_floats: true but was overridden). Unstable: loss spike after epoch ~15; mode collapse to accel/coast. Config:
config_files/pretrain/bc/pretrain_config_bc_v3.yaml.v3_only_vis: Same as v3 but use_full_iqn: false, use_floats: false (visual backbone only). Stable: val_loss ~0.99. Recommended for img 100 FPS dataset. Config:
config_files/pretrain/bc/pretrain_config_bc_v3_only_vis.yaml.v3_multi_offset: Same base as v3 (use_full_iqn: true, use_floats: true) with multi-offset BC:
bc_time_offsets_ms: [0, 10, 20, ..., 100](11 heads),bc_offset_weights: [5, 4, 3, 2, 1, 1, ...]. Stable: train_acc 0.90, val_acc 0.89; no overfitting. RL-aligned prev_actions (no target leakage). Config:config_files/pretrain/bc/pretrain_config_bc_v3_multi_offset.yaml.v3_current_tick: Same base as v3 (use_full_iqn: true, use_floats: true) but single head (current tick only, bc_time_offsets_ms=[0]),
preprocess_cache_dir: cache/v1.1. Stable: val_acc 0.973, val_loss 0.102. Config:config_files/pretrain/bc/pretrain_config_bc_v3_current_tick.yaml. See “Experiment: Single-head current tick vs multi-offset (v3_current_tick vs v3_multi_offset)” for comparison.v4_multi_offset: Same architecture and config as v3_multi_offset (use_full_iqn: true, use_floats: true, 11 offset heads) but the BC forward pass uses the dueling formula
Q = V + A - A.mean(dim=-1)so that V_head receives gradients during BC. In v3, only A_heads were in the loss path; in v4 both V_head and A_heads are trained. The savediqn_bc.ptcontains trained V_head and A_head (offset 0) for RL injection. Config:config_files/pretrain/bc/pretrain_config_bc_v4_multi_offset.yaml. Run:python scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v4_multi_offset.yaml. Compare to v3 with:python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3_multi_offset output/ptretrain/bc/v4_multi_offset --interval 5.
Multi-offset analysis: For runs with bc_time_offsets_ms (e.g. v2_multi_offset), scripts/analyze_pretrain_bc.py prints a Per-offset validation accuracy block (last epoch and best epoch by val_loss). Compare v2_next_tick vs v2_multi_offset to see whether predicting several time offsets helps overall or per-offset accuracy. Example: python scripts/analyze_pretrain_bc.py --base-dir output/ptretrain/bc v2_next_tick v2_multi_offset --interval 5.
Detailed Metrics Analysis (by Epoch)
Methodology: Metrics are compared at epoch checkpoints (0, 5, 10, 15, 20, 24) over the common epoch window (0–24). Source: Lightning CSV; use scripts/analyze_pretrain_bc.py to reproduce. Per-action accuracy is reported with action names (accel, left+accel, right+accel, coast, left, right, brake, etc.), not only class indices.
Train / val loss and overall accuracy at checkpoints
v1: epoch 0 — train_loss 1.31, val_loss 1.07, val_acc 0.57; epoch 10 — 0.85 / 1.02 / 0.61; epoch 24 — 0.79 / 1.04 / 0.62.
v1.1: epoch 0 — 1.30 / 1.09 / 0.59; epoch 10 — 0.89 / 1.00 / 0.59; epoch 24 — 0.83 / 1.05 / 0.62.
At epoch 24, v1 has lower val_loss (1.04 vs 1.05) and similar val_acc. v1.1 trained to 50 epochs ends with higher val_loss (1.12).
Combined analysis (loss + per-action accuracy)
Best epoch by val_loss (script analyze_pretrain_bc.py):
v1: best epoch = 14 (val_loss 0.997, val_acc 0.61, main_actions_val_acc 0.49).
v1.1: best epoch = 11 (val_loss 0.994, val_acc 0.60, main_actions_val_acc 0.42).
At these epochs val_loss is minimal but main_actions_val_acc (mean over accel, left+accel, right+accel, coast, left+accel+brake, right+accel+brake) is lower than at epoch 20–24. So stopping purely at min val_loss yields the best loss but worse per-action accuracy; a better compromise is to stop around 20–25 epochs when both loss and per-action acc are good.
Per-action validation accuracy (action names)
At last epoch (v1 at 24, v1.1 at 49):
accel (0): v1 0.71, v1.1 0.71
left+accel (1): v1 0.71, v1.1 0.70
right+accel (2): v1 0.52, v1.1 0.53
coast (3): v1 0.58, v1.1 0.41 (v1.1 drops with more training)
left (4), right (5), brake (6), left+brake (7), right+brake (8), accel+brake (9): near zero in both (very few or no val samples)
left+accel+brake (10): v1 0.39, v1.1 0.41
right+accel+brake (11): v1 0.33, v1.1 0.33
So the model learns accel, left+accel, right+accel, coast, and the two accel+brake turn actions; rare actions (brake-only, left/right without accel) stay at 0. Training longer (v1.1 to 50 epochs) does not improve these and can slightly hurt coast.
Per-action accuracy vs training (epoch)
The figure below shows validation accuracy for each action (accel, left+accel, right+accel, coast, etc.) over epochs for v1 and v1.1. Main actions (0, 1, 2, 3, 10, 11) show clear learning curves; rare actions (4–9) stay near zero.
Experiment: IQN-style image normalization (v1.1 vs v1.2)
Overview: v1.2 is identical to v1.1 except image_normalization: “iqn” (input (x - 0.5) / 0.5 on [0,1] cache). Both use the same visual backbone (vis/v1) trained without IQN normalization. Comparison is by epoch (same 50 epochs, same data and seed).
Metrics at epoch checkpoints (from ``analyze_pretrain_bc.py``):
Epoch 0: v1.1 train_loss 1.30, val_loss 1.09, val_acc 0.59; v1.2 train_loss 1.82, val_loss 1.12, val_acc 0.57 — v1.2 starts with higher train loss (normalization changes input distribution; backbone was trained on [0,1]).
Epoch 20: v1.1 val_loss 1.02, val_acc 0.61; v1.2 val_loss 0.97, val_acc 0.61 — v1.2 pulls ahead on val_loss.
Epoch 49: v1.1 val_loss 1.12, val_acc 0.625; v1.2 val_loss 0.949, val_acc 0.618 — v1.2 has ~15% lower val_loss; val_acc nearly the same.
Best epoch by val_loss:
v1.1: best epoch = 11, val_loss = 0.994, main_actions_val_acc = 0.42.
v1.2: best epoch = 38, val_loss = 0.941, main_actions_val_acc = 0.52 — both better val_loss and better per-action accuracy at the best checkpoint.
Per-action validation accuracy (last epoch):
accel: v1.1 0.71, v1.2 0.80
left+accel: v1.1 0.70, v1.2 0.56
right+accel: v1.1 0.53, v1.2 0.52
coast: v1.1 0.41, v1.2 0.45
left+accel+brake / right+accel+brake: similar or slightly lower in v1.2 at epoch 49.
Conclusion (normalization): IQN-style normalization at BC input reduces validation loss clearly (~15% at 50 epochs) and gives a better best-epoch (lower val_loss and higher main_actions_val_acc). Overall val_acc at the last epoch is slightly lower in v1.2, but the model generalizes better in terms of loss. Recommendation: use image_normalization: “iqn” for BC pretrain when the encoder will be loaded into IQN. Note: the visual backbone in both experiments was pretrained without IQN normalization; aligning Level 0 pretrain with IQN normalization in a future run may yield further gains.
Experiment: Multi-offset BC (v2_multi_offset)
Goal: Evaluate multi-offset BC (predict action at several time offsets from the last frame: -10 ms, 0 ms, +10 ms, +100 ms) to see whether auxiliary heads improve learning and whether per-offset accuracy is useful for analysis.
Config: Base = config_files/pretrain/bc/pretrain_config_bc_v2_next_tick.yaml (vis v2, IQN norm, next_tick). Minimal override: run_name: v2_multi_offset, bc_time_offsets_ms: [-10, 0, 10, 100], bc_offset_weights: [0.2, 1.0, 0.5, 0.3]. Full config: config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset.yaml.
Cache: When bc_time_offsets_ms has more than one value, a full BC cache is built (train.npy, train_actions.npy with shape (N, n_offsets), val.*, cache_meta.json). After build, consistency is verified: train_actions.npy shape must match (n_train, len(bc_time_offsets_ms)) and meta must contain bc_time_offsets_ms, n_actions, n_train, n_val, source_signature. Re-running with the same offsets reuses the cache.
How to run:
# After vis v2 is trained (encoder at output/ptretrain/vis/v2/encoder.pt):
.\.venv\Scripts\python.exe scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset.yaml
Outputs: Run directory output/ptretrain/bc/v2_multi_offset/ with encoder.pt, pretrain_meta.json, csv/metrics.csv (or csv/version_0/metrics.csv), and TensorBoard logs. Meta includes bc_time_offsets_ms and bc_offset_weights. CSV columns include train_acc_offset_ms_-10, val_acc_offset_ms_0, val_acc_offset_ms_10, val_acc_offset_ms_100 (and train variants).
How to analyze (doc/exp):
.\.venv\Scripts\python.exe scripts/analyze_pretrain_bc.py output/ptretrain/bc/v2_multi_offset output/ptretrain/bc/v2 output/ptretrain/bc/v2_next_tick --interval 5
Use documented values for v2 and v2_next_tick: the directory output/ptretrain/bc/v2_next_tick/ was overwritten by the n_stack=3 run (see “Experiment: n_stack 1 vs 3”), so its logs are for stack3, not the original next_tick. For v2_next_tick (n_stack=1) use the numbers from the “Experiment: BC target current_tick vs next_tick” and “Experiment: n_stack 1 vs 3” subsections below. For v2 (current_tick) use “Run Analysis (v2 chain)” and “Experiment: BC target current_tick vs next_tick”.
The script prints Per-offset validation accuracy for v2_multi_offset (last epoch and best epoch by val_loss). Compare val_acc_offset_ms_0 to v2 (both are offset 0 / current tick); compare val_acc_offset_ms_10 to v2_next_tick (both are next tick, +10 ms).
Semantics of baselines:
v2 (config
pretrain_config_bc_v2.yaml): bc_target: current_tick → predicts action at the same tick as the image = offset 0 (MDP-aligned π(a_t|s_t)). Documented: val_acc 0.616 (last epoch), best epoch 38.v2_next_tick (config
pretrain_config_bc_v2_next_tick.yaml): bc_target: next_tick → predicts action at the next tick = offset +10 ms (π(a_{t+1}|s_t)). Documented (n_stack=1, before overwrite): val_acc 0.552, best epoch 18. Do not use metrics from the currentv2_next_tickdirectory (they are for stack3).
Results and interpretation (v2_multi_offset vs v2 and v2_next_tick, 50 epochs; baseline values from documentation):
Main prediction (offset 0, current tick): val_acc_offset_ms_0 in v2_multi_offset is the accuracy of the head that predicts the action at the current frame (same as v2). In the run with action-timeline labels (cache rebuilt after switching to manifest
"actions"+step_ms), v2_multi_offset achieved val_acc_offset_ms_0 = 0.620 (last epoch) vs v2 (current_tick, single head) val_acc 0.616 (doc / same run). Multi-offset training gives comparable or slightly better main (0-offset) prediction than the single-head current_tick baseline; the shared backbone benefits from the multi-task signal.Forward offset +10 ms (next tick): val_acc_offset_ms_10 corresponds to the same target as v2_next_tick. v2_multi_offset val_acc_offset_ms_10 = 0.618 vs v2_next_tick documented val_acc 0.552 (n_stack=1). So the multi-offset head at +10 ms is much higher than the single-head next_tick model; multi-task training helps the +10 ms head.
Difference between offsets (with action timeline): With labels from the action timeline (not closest frame), per-offset accuracies at the last epoch differ as expected: val_acc_offset_ms_-10 = 0.623, val_acc_offset_ms_0 = 0.620, val_acc_offset_ms_10 = 0.618, val_acc_offset_ms_100 = 0.590. Past and current are slightly easier than +10 ms; +100 ms is clearly harder (~3 pp lower), so predicting action 100 ms ahead is more difficult. This confirms that 0 vs +10 ms targets are now distinct and the metric reflects real offset difficulty.
Action timings (not frame timings): Multi-offset labels use the action timeline from the manifest (
manifest.json"actions"+metadata.jsonstep_ms) when present: action at T+d ms =actions[round((T+d)/step_ms)]. So offset 0 and +10 ms refer to actual game-step actions (what was pressed at that time), not “closest captured frame”. That gives distinct targets for 0 vs +10 ms regardless of capture FPS. If a replay has no"actions"or nostep_ms, the code falls back to “closest entry by time_ms” (frame-based), which at low FPS can make 0 and +10 identical.Loss note: v2_multi_offset has higher reported val_loss (e.g. ~1.93) than v2 (~0.95) because the loss is a weighted sum of four cross-entropies (one per offset). So val_loss is not directly comparable; use val_acc and val_acc_offset_ms_* for comparison.
Takeaway: Multi-offset BC with action-timeline labels yields distinct per-offset accuracies: -10/0/10 ms similar (~0.62), +100 ms lower (~0.59). The 0-offset head is on par with or slightly better than single-head v2 (current_tick). The +10 ms head is much better than single-head v2_next_tick. When comparing to baselines, use documented values for v2 and v2_next_tick, not the current v2_next_tick directory (overwritten by stack3).
Interpretation (generic): Compare val_acc_offset_ms_0 to v2 (current_tick, single head) and val_acc_offset_ms_10 to v2_next_tick (next_tick, single head). If val_acc_offset_ms_0 is close to or higher than v2’s val_acc, the shared backbone benefits from multi-task learning. If val_acc_offset_ms_10 or val_acc_offset_ms_100 are high, the model learns to anticipate; if they are lower than offset 0, current-tick prediction remains the main signal.
Experiment: vis backbone + a_head only (v2_multi_offset_ahead vs v2_multi_offset)
Goal: Compare v2_multi_offset (four Linear heads) with v2_multi_offset_ahead (same data and offsets, but use_actions_head: true: four MLP heads in IQN A_head layout). The latter trains only vis backbone + action heads (no full IQN, no float head) and saves actions_head.pt for direct injection into RL IQN.
Configs:
v2_multi_offset:
config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset.yaml—run_name: v2_multi_offset,bc_time_offsets_ms: [-10, 0, 10, 100],bc_offset_weights: [0.2, 1.0, 0.5, 0.3], nouse_actions_head(plain Linear heads).v2_multi_offset_ahead:
config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead.yaml— same as above +use_actions_head: true,save_actions_head: true,dense_hidden_dimension: 1024;run_name: v2_multi_offset_ahead.
How to run (ahead):
.\.venv\Scripts\python.exe scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v2_multi_offset_ahead.yaml
Outputs (v2_multi_offset_ahead): output/ptretrain/bc/v2_multi_offset_ahead/ — encoder.pt, actions_head.pt (offset 0, IQN A_head layout), pretrain_meta.json, metrics.csv, TensorBoard. Same per-offset CSV columns as v2_multi_offset.
Run summary (50 epochs, from ``analyze_pretrain_bc.py``):
Metric |
v2_multi_offset (Linear) |
v2_multi_offset_ahead (MLP A_head) |
v2_multi_offset_ahead_tuned |
|---|---|---|---|
train_acc (last epoch) |
0.693 |
0.792 |
0.678 |
val_acc (last epoch) |
0.612 |
0.552 |
0.591 |
train_loss (last epoch) |
1.574 |
1.049 |
1.647 |
val_loss (last epoch) |
1.932 |
2.884 |
2.080 |
Best epoch by val_loss |
49 |
14 |
16 |
val_loss at best epoch |
1.932 |
2.004 |
2.029 |
val_acc at best epoch |
0.612 |
0.594 |
0.591 |
main_actions_val_acc at best |
0.515 |
0.457 |
0.420 |
Epochs run |
50 |
50 |
27 (early stop) |
Per-offset validation accuracy (last epoch):
Offset (ms) |
v2_multi_offset |
v2_multi_offset_ahead |
v2_multi_offset_ahead_tuned |
|---|---|---|---|
-10 |
0.6227 |
0.5610 |
0.6007 |
0 |
0.6200 |
0.5618 |
0.5941 |
10 |
0.6176 |
0.5497 |
0.5957 |
100 |
0.5896 |
0.5364 |
0.5753 |
v2_multi_offset_ahead at best epoch (14): val_acc_offset_ms_-10 = 0.600, val_acc_offset_ms_0 = 0.606, val_acc_offset_ms_10 = 0.595, val_acc_offset_ms_100 = 0.576. So even at its best, the A_head run stays ~1–2 pp below Linear on each offset.
Tuned hyperparameters (v2_multi_offset_ahead_tuned): Config pretrain_config_bc_v2_multi_offset_ahead_tuned.yaml uses lr: 0.0002 (lower than 0.0005), weight_decay: 0.01 (AdamW), and early_stopping: true with patience: 10. Training stops at epoch 27 (best val_loss at epoch 16). Val_acc 0.591 vs 0.552 (untuned ahead); per-offset accuracies 0.60 / 0.59 / 0.60 / 0.58 — much closer to Linear and no overfitting. Per-action at last epoch: accel 0.80, left+accel 0.55, right+accel 0.49, coast 0.15; balanced and suitable for RL merge. Use this config when you need A_head for RL and want better validation without manually picking a checkpoint.
Reg-only, no early stop (v2_multi_offset_ahead_reg): Config pretrain_config_bc_v2_multi_offset_ahead_reg.yaml uses lr: 0.0001, weight_decay: 0.02, early_stopping: false — full 50 epochs. Reaches val_acc 0.592 at epoch 49 (best val_loss at epoch 35 = 2.014). Per-offset at last epoch: 0.597 / 0.597 / 0.598 / 0.576 — best per-offset among A_head variants (before dropout). Train_acc 0.676 (no overfitting). Use when you want a full 50-epoch run without early stopping and comparable or slightly better val than tuned.
Dropout (v2_multi_offset_ahead_dropout): Config pretrain_config_bc_v2_multi_offset_ahead_dropout.yaml adds dropout: 0.2 on features before the action head (same lr/weight_decay as reg, no early stop). Best A_head run: val_acc 0.595, val_loss 1.989 at epoch 49; best val_loss 1.979 at epoch 40. Per-offset: 0.603 / 0.600 / 0.600 / 0.578 — highest among A_head variants and closest to Linear (0.623/0.620/0.618/0.590). Recommended for RL merge when you want best val without early stopping.
Dropout + inner (v2_multi_offset_ahead_dropout_inner): Config pretrain_config_bc_v2_multi_offset_ahead_dropout_inner.yaml adds action_head_dropout: 0.1 between the two Linear layers of A_head (plus dropout 0.2 on features). Best A_head so far: val_acc 0.597, val_loss 1.971 at epoch 49; per-offset 0.605 / 0.603 / 0.602 / 0.579; main_actions_val_acc 0.476, coast 0.374. Saved actions_head.pt is remapped to IQN layout (no dropout in file). Recommended for RL merge.
Interpretation:
v2_multi_offset (Linear) does not overfit by epoch 49: best epoch = 49, val_acc 0.612, per-offset accuracies ~0.59–0.62. Higher capacity is not needed for this data.
v2_multi_offset_ahead (MLP A_head) overfits strongly: best epoch by val_loss = 14; afterwards val_loss rises (2.0 → 2.88) and val_acc falls (0.59 → 0.55) while train_acc keeps rising to 0.79. The MLP head has more parameters and fits the training set better but generalizes worse.
Per-action (epoch 49): Linear: accel 0.78, left+accel 0.59, right+accel 0.54, coast 0.43, left+accel+brake 0.42, right+accel+brake 0.33. A_head: accel 0.50, left+accel 0.76, right+accel 0.53, coast 0.41, left+accel+brake 0.31, right+accel+brake 0.27. A_head trades accel for left+accel and is worse on coast and brake-turn actions; overall val and main_actions are lower.
Recommendations:
Best validation quality (multi-offset): Use v2_multi_offset (Linear heads). It gives better val_acc and per-offset accuracy without overfitting.
RL merge (vis + A_head only): Use v2_multi_offset_ahead only if you need
actions_head.ptfor IQN injection. In that case enable early stopping (e.g. patience 5–10 on val_loss) or take the checkpoint at best epoch ~14; the default save at the end of 50 epochs is from an overfit model (val_acc 0.55, best was 0.59 at epoch 14).RL merge with better val (recommended): Use v2_multi_offset_ahead_tuned (config
pretrain_config_bc_v2_multi_offset_ahead_tuned.yaml): lower lr (0.0002), weight_decay (0.01), and early_stopping. Reaches val_acc 0.591 and per-offset ~0.59–0.60, stops around epoch 26; per-action balance is sane (accel 0.80, no collapse). Savesactions_head.ptfor RL merge. Alternative without early stop: v2_multi_offset_ahead_reg (pretrain_config_bc_v2_multi_offset_ahead_reg.yaml): lr 0.0001, weight_decay 0.02, full 50 epochs — val_acc 0.592, best val_loss at epoch 35, per-offset ~0.597–0.598. Best A_head (no early stop): v2_multi_offset_ahead_dropout (pretrain_config_bc_v2_multi_offset_ahead_dropout.yaml): reg + dropout: 0.2 — val_acc 0.595, val_loss 1.989, per-offset ~0.60–0.603. Best overall A_head: v2_multi_offset_ahead_dropout_inner (pretrain_config_bc_v2_multi_offset_ahead_dropout_inner.yaml): dropout 0.2 + action_head_dropout: 0.1 — val_acc 0.597, val_loss 1.971, per-offset ~0.605–0.603.Reproduce: Run the analysis script to get full per-epoch and per-action tables:
.\.venv\Scripts\python.exe scripts/analyze_pretrain_bc.py output/ptretrain/bc/v2_multi_offset output/ptretrain/bc/v2_multi_offset_ahead output/ptretrain/bc/v2_multi_offset_ahead_tuned output/ptretrain/bc/v2_multi_offset_ahead_reg --interval 5
Experiment: Full IQN-aligned chain (vis v2 + BC v2)
Overview: This experiment chain uses two config files so that both Level 0 (visual) and Level 1 (BC) use IQN-style normalization end-to-end.
Visual backbone v2 — config
config_files/pretrain/vis/pretrain_config_vis_iqn.yaml:run_name: v2,image_normalization: "iqn". Output:output/ptretrain/vis/v2/encoder.pt.BC v2 — config
config_files/pretrain/bc/pretrain_config_bc_v2.yaml:run_name: v2,encoder_init_path: output/ptretrain/vis/v2/encoder.pt,image_normalization: "iqn". Output:output/ptretrain/bc/v2/.
Level 0 (visual) v2 results: Vis v2 was trained with IQN normalization and preprocess_cache_dir: cache/v0; 50 epochs (no early stopping). Final train_loss 0.206, val_loss 0.207. Encoder saved to output/ptretrain/vis/v2/encoder.pt.
Commands:
# 1. Train visual backbone with IQN normalization (output: output/ptretrain/vis/v2/)
python scripts/pretrain_visual_backbone.py --config config_files/pretrain/vis/pretrain_config_vis_iqn.yaml
# 2. Train BC with vis v2 encoder and IQN normalization (output: output/ptretrain/bc/v2/)
python scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v2.yaml
Analysis (after BC v2 completes): Compare v1.2 (BC with IQN norm, backbone from vis/v1 without IQN) vs v2 (full alignment):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1.2 output/ptretrain/bc/v2 --interval 5
Run Analysis (v2 chain)
vis v2: Level 0 with
image_normalization: "iqn",preprocess_cache_dir: cache/v0; 50 epochs (no early stopping); train_loss 0.206, val_loss 0.207. CSV:output/ptretrain/vis/v2/csv/metrics.csv.BC v2: Encoder from vis/v2,
image_normalization: "iqn", cache v0; 50 epochs. Final val_loss 0.948, val_acc 0.616. CSV:output/ptretrain/bc/v2/csv/metrics.csv.BC v2_next_tick: Same as BC v2 but bc_target: next_tick (config
pretrain_config_bc_v2_next_tick.yaml). Original run (n_stack=1): final val_loss 1.116, val_acc 0.552 (this run was later overwritten by the stack3 experiment; metrics are in the “Experiment: n_stack 1 vs 3” subsection). Current dir contains the stack3 run (n_stack=3): val_loss 1.074, val_acc 0.552; seepretrain_meta.jsonforn_stack: 3.
Detailed Metrics Analysis (v1.2 vs v2, by epoch)
Methodology: Metrics are compared by epoch (same 50 epochs for BC). Source: Lightning CSV; use scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1.2 output/ptretrain/bc/v2 --interval 5 to reproduce. Report train/val loss, val_acc at checkpoints; best epoch by val_loss (val_loss, val_acc, main_actions_val_acc); and per-action validation accuracy with action names.
Results (v1.2 vs v2):
Summary: Both 50 epochs. v1.2: train_acc 0.706, val_acc 0.618, train_loss 0.763, val_loss 0.949. v2: train_acc 0.701, val_acc 0.616, train_loss 0.776, val_loss 0.948. Val_loss is virtually the same; v1.2 has slightly higher overall val_acc.
Best epoch by val_loss: Both best at epoch 38. v1.2: val_loss 0.9411, val_acc 0.6159, main_actions_val_acc 0.5169. v2: val_loss 0.9438, val_acc 0.6153, main_actions_val_acc 0.5072. So v1.2 has slightly better main_actions_val_acc at the best checkpoint (better for action prediction accuracy on the six main actions).
Per-action val_acc (last epoch, epoch 49):
accel: v1.2 0.801, v2 0.797 — v1.2 slightly higher.
left+accel: v1.2 0.564, v2 0.562 — tied.
right+accel: v1.2 0.524, v2 0.522 — tied.
coast: v1.2 0.451, v2 0.639 — v2 much better on coast.
left+accel+brake: v1.2 0.419, v2 0.394 — v1.2 higher.
right+accel+brake: v1.2 0.292, v2 0.301 — v2 slightly higher.
Conclusion for action prediction accuracy: v1.2 is marginally better for overall val_acc and main_actions_val_acc (mean over the six main actions) at the best epoch. v2 is clearly better for coast (0.64 vs 0.45). For best overall action prediction accuracy, prefer v1.2 (backbone from vis/v1 + IQN norm at BC). If coast prediction is a priority, v2 (full IQN-aligned chain) is better. Val_loss is effectively tied (0.948–0.949).
Experiment: BC target current_tick vs next_tick (v2 vs v2_next_tick)
Overview: This experiment compares two BC v2 runs that differ only in bc_target: v2 uses bc_target: current_tick (predict action at the same tick as the image), v2_next_tick uses bc_target: next_tick (predict action at the next tick). Same encoder (vis v2), same data, same hyperparameters (50 epochs, batch 4096, lr 0.0005). Configs: config_files/pretrain/bc/pretrain_config_bc_v2.yaml vs config_files/pretrain/bc/pretrain_config_bc_v2_next_tick.yaml.
How action prediction accuracy changed (next_tick vs current_tick):
Overall validation accuracy (last epoch): v2 (current_tick) 0.616 vs v2_next_tick 0.552 — next_tick is ~6.4 pp lower.
Best epoch by val_loss: v2 best at epoch 38 (val_loss 0.944, main_actions_val_acc 0.507); v2_next_tick best at epoch 18 (val_loss 1.091, main_actions_val_acc 0.315). So next_tick has much lower per-action accuracy at the best checkpoint (~19 pp lower main_actions_val_acc).
Per-action validation accuracy (epoch 49):
accel: v2 0.797, v2_next_tick 0.702 — next_tick worse.
left+accel: v2 0.562, v2_next_tick 0.507 — next_tick worse.
right+accel: v2 0.522, v2_next_tick 0.504 — similar.
coast: v2 0.639, v2_next_tick 0.000 — next_tick has no coast accuracy (likely no or very few coast labels in the next-tick target distribution).
left+accel+brake: v2 0.394, v2_next_tick 0.196 — next_tick much worse.
right+accel+brake: v2 0.301, v2_next_tick 0.118 — next_tick much worse.
Conclusion: bc_target: next_tick substantially reduces action prediction accuracy compared to current_tick: lower overall val_acc, much lower main_actions_val_acc, and coast drops to 0 (next-tick targets may rarely be coast, or the task is harder). For best action prediction accuracy, use bc_target: current_tick (v2). Use next_tick only if the downstream use case explicitly requires predicting the next tick’s action.
Reproduce:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v2 output/ptretrain/bc/v2_next_tick --interval 5
Experiment: n_stack 1 vs 3 (temporal stack, next_tick)
Overview: This experiment compares n_stack=1 (single frame per sample) vs n_stack=3 (three consecutive frames per sample) for BC pretrain with bc_target: next_tick. Goal: determine whether feeding multiple past images into the model improves action prediction accuracy enough to justify the extra memory and compute.
Time between frames: Replay frames are captured by scripts/capture_replays_tmnf.py. The interval between consecutive frames is 1000 / fps ms (--fps is frames per simulation second; see TMNF replay download and frame capture). Typical values: 10 FPS → 100 ms between frames; 64 FPS → ~15.6 ms. With n_stack=3, the three frames span (n_stack − 1) × interval in time: e.g. at 10 FPS the stack covers 2×100 = 200 ms of simulation time; at 64 FPS about 31 ms. The game engine step is 10 ms (ms_per_tm_engine_step in config); capture can be every step (100 FPS) or sub-sampled (e.g. 10 or 64 FPS). Check metadata.json in each replay dir for fps and step_ms to see the actual interval used for your data.
Configs:
Baseline (n_stack=1):
config_files/pretrain/bc/pretrain_config_bc_v2_next_tick.yaml—n_stack: 1,preprocess_cache_dir: cache/v0,cache_load_in_ram: true,workers: 4.Experimental (n_stack=3):
config_files/pretrain/bc/pretrain_config_bc_v2_next_tick_stack3.yaml—n_stack: 3,preprocess_cache_dir: cache/v0_stack3,cache_load_in_ram: false,workers: 1.
Configuration changes (n_stack=3 vs n_stack=1):
n_stack: 1 → 3 (three consecutive frames per sample; model gets temporal context).
preprocess_cache_dir:
cache/v0→cache/v0_stack3(separate cache because cache format depends on n_stack).cache_load_in_ram:
true→false(see Memory and RAM below).workers: 4 → 1 (reduced to avoid OOM when using n_stack=3).
All other training settings are the same (batch_size 4096, epochs 50, lr 0.0005, same encoder init, image_normalization “iqn”, bc_target next_tick).
Memory and RAM
Using n_stack=3 significantly increases RAM usage:
Cache: Each sample is 3× larger (3 frames instead of 1). Preprocessed cache size grows by a factor of ~3. Loading the full cache into RAM (
cache_load_in_ram: true) with n_stack=3 can cause out-of-memory errors on machines with limited RAM.Training batch: Each batch holds 3× more pixel data per sample (e.g. batch_size 4096 × 3 × 1 × H × W). This increases GPU and host memory during training.
Mitigation in the stack3 config:
cache_load_in_ram: falsekeeps the cache on disk (memory-mapped) instead of loading it entirely into RAM;workers: 1reduces the number of DataLoader workers to lower peak RAM. If you still hit OOM, consider reducingbatch_sizeor building the cache with a smaller dataset.
Run analysis
v2_next_tick (n_stack=1) — original run, overwritten: Config
pretrain_config_bc_v2_next_tick.yaml. Metrics below are from documentation only (recorded before the run was overwritten). Final val_loss 1.116, val_acc 0.552; best epoch by val_loss = 18 (val_loss 1.091, main_actions_val_acc 0.315). Per-action (epoch 49): accel 0.702, left+accel 0.507, right+accel 0.504, coast 0.000, left+accel+brake 0.196, right+accel+brake 0.118.Current ``output/ptretrain/bc/v2_next_tick/`` = v2_next_tick_stack3 (n_stack=3): The directory was overwritten by the stack3 run (config
pretrain_config_bc_v2_next_tick_stack3.yaml).pretrain_meta.jsonin that dir shows n_stack: 3. Metrics: final val_loss 1.074, val_acc 0.552; best epoch by val_loss = 29 (val_loss 1.066, main_actions_val_acc 0.327). Per-action (epoch 49): accel 0.744, left+accel 0.504, right+accel 0.461, coast 0.000, left+accel+brake 0.173, right+accel+brake 0.113.
Comparison: documented v2_next_tick (n_stack=1) vs current run (n_stack=3)
Metric |
v2_next_tick (n_stack=1, from doc) |
Current dir (n_stack=3) |
|---|---|---|
Final val_loss |
1.116 |
1.074 (lower) |
Final val_acc |
0.552 |
0.552 (tie) |
Best epoch (by val_loss) |
18 |
29 |
Best-epoch val_loss |
1.091 |
1.066 (lower) |
Best-epoch main_actions_val_acc |
0.315 |
0.327 (slightly higher) |
accel (last epoch) |
0.702 |
0.744 (higher) |
left+accel (last epoch) |
0.507 |
0.504 (similar) |
right+accel (last epoch) |
0.504 |
0.461 (lower) |
left+accel+brake (last epoch) |
0.196 |
0.173 (lower) |
right+accel+brake (last epoch) |
0.118 |
0.113 (similar) |
Conclusion: With n_stack=3 (current overwritten run), val_loss is better (1.074 vs 1.116 at last epoch; 1.066 vs 1.091 at best epoch) and main_actions_val_acc at best epoch is slightly higher (0.327 vs 0.315). accel accuracy at the last epoch is clearly higher (0.744 vs 0.702). Some actions are slightly worse with n_stack=3 (right+accel, left+accel+brake). Overall, temporal stack (n_stack=3) gives a small improvement in validation loss and best-epoch main-actions accuracy, and a clear gain on accel, at the cost of much higher RAM usage (see Memory and RAM above). The gain may not justify the memory cost unless accel or val_loss is critical.
Reproduce comparison: The original n_stack=1 run was overwritten, so side-by-side script comparison is not possible. To reproduce metrics for the current (stack3) run: python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v2_next_tick --interval 5. The n_stack=1 numbers in the table above are from the documentation (recorded before overwrite).
Results and conclusions
Whether multiple past frames help: The comparison above (documented v2_next_tick n_stack=1 vs current run n_stack=3) shows that n_stack=3 gives a small improvement: lower val_loss (1.074 vs 1.116), better best-epoch val_loss and main_actions_val_acc, and higher accel accuracy. Some per-action accuracies are slightly worse (right+accel, left+accel+brake). Conclusion: Temporal context (3 frames) helps a bit on loss and accel, but the gain is modest and comes with much higher RAM usage (see Memory and RAM).
Trade-off: n_stack=3 provides temporal information but increases RAM usage; the stack3 config uses
cache_load_in_ram: falseandworkers: 1to avoid OOM. Whether to use n_stack=3 depends on whether the small accuracy/loss gain justifies the memory cost.
Recommendations
If you have limited RAM, use n_stack=1 or ensure cache_load_in_ram: false and lower
workers(and optionallybatch_size) for n_stack=3.After running both experiments with distinct run names, use
scripts/analyze_pretrain_bc.pyto compare by epoch and decide whether the gain from n_stack=3 justifies the memory and compute cost.
Experiment: Full IQN + floats vs visual-only on img 100 FPS (v3 vs v3_only_vis)
Overview: This experiment compares two BC runs on the new img dataset (frames captured at 100 FPS via TMInterface; see TMNF replay download and frame capture). Both use the same data (maps/img, cache cache/v1), encoder init from vis v2, and IQN image normalization. The only difference is the BC architecture:
v3 (
pretrain_config_bc_v3.yaml): use_full_iqn: true — trains the full IQN (img_head + iqn_fc + A_head + V_head). In practice run without float state inputs (use_floats: false or override). Intended for 1:1 transfer into RL IQN.v3_only_vis (
pretrain_config_bc_v3_only_vis.yaml): use_full_iqn: false, use_floats: false — trains only the visual backbone + action head (no full IQN, no float inputs). Same backbone, image-only.
Goal: Determine whether full IQN + floats improves action prediction accuracy on the high-FPS img dataset, or whether visual-only training is more stable and effective.
Dataset: maps/img (TMInterface capture at 100 FPS, interval ~10 ms between frames), preprocess_cache_dir: cache/v1. n_train ≈ 608,901, n_val ≈ 66,006.
Key findings
Training stability: v3 (full IQN, no floats) shows severe training instability after ~epoch 10–15. Train_loss and val_loss spike (epoch 20: train_loss 2.05, val_loss 3.19; epoch 40: val_loss 6.14; epoch 49: train_loss 3.77, val_loss 3.87). v3_only_vis trains stably: val_loss decreases monotonically and plateaus around 0.98–0.99.
Mode collapse (v3): v3 collapses to predicting mostly accel (val_acc_class_0 ≈ 0.9999) and coast (≈ 0.82); left+accel, right+accel, left+accel+brake, right+accel+brake all go to 0. main_actions_val_acc at best epoch = 0.22 (very low).
v3_only_vis: More balanced per-action accuracy: accel 0.99, left+accel 0.007, right+accel 0.01, coast 0.95, brake 0.16. main_actions_val_acc at best epoch = 0.33 (higher than v3).
Best epoch by val_loss: v3 best at epoch 8 (val_loss 1.008) before instability; v3_only_vis best at epoch 42 (val_loss 0.984).
Conclusion: On the img 100 FPS dataset, visual-only (v3_only_vis) is stable. Full IQN without floats (v3) leads to training instability and mode collapse (accel/coast dominance). v3_multi_offset (full IQN + floats with multi-offset) is stable and achieves much higher accuracy; use it when full IQN + floats is needed (see “Experiment: Multi-offset BC on img 100 FPS”).
How to run
.\.venv\Scripts\python.exe scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v3_only_vis.yaml
.\.venv\Scripts\python.exe scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v3.yaml
Reproduce
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3 output/ptretrain/bc/v3_only_vis --interval 5
Experiment: Multi-offset BC on img 100 FPS (v3_multi_offset)
Overview: This experiment tests multi-offset BC on the img 100 FPS dataset with full IQN + floats. Unlike v3 (single head, unstable) and v3_only_vis (visual-only, stable), v3_multi_offset trains 11 heads at offsets 0, 10, 20, …, 100 ms with weighted loss (higher weight on nearer offsets: 5, 4, 3, 2, 1, 1, …). Goal: see whether multi-offset regularizes full IQN training and avoids the collapse seen in v3.
Config: config_files/pretrain/bc/pretrain_config_bc_v3_multi_offset.yaml — same base as v3 (use_full_iqn: true, use_floats: true, maps/img, cache v1) plus:
bc_time_offsets_ms: [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]bc_offset_weights: [5.0, 4.0, 3.0, 2.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
Note: Metrics below are from a run without target leakage. A prior run had inflated metrics because prev_actions in the float inputs incorrectly included the current action (the prediction target). This was fixed to match RL (prev_actions = actions strictly before the current step).
Key findings
Overfitting: No overfitting. train_acc 0.900, val_acc 0.894 (last epoch); train_loss 4.15, val_loss 4.41. Best epoch by val_loss = 49 (last epoch); val_loss and val_acc improve steadily through training. Multi-offset acts as a regularizer and the model generalizes well.
Stability: Unlike v3 (loss spike after epoch 15, mode collapse), v3_multi_offset trains stably. Loss decreases monotonically; no collapse.
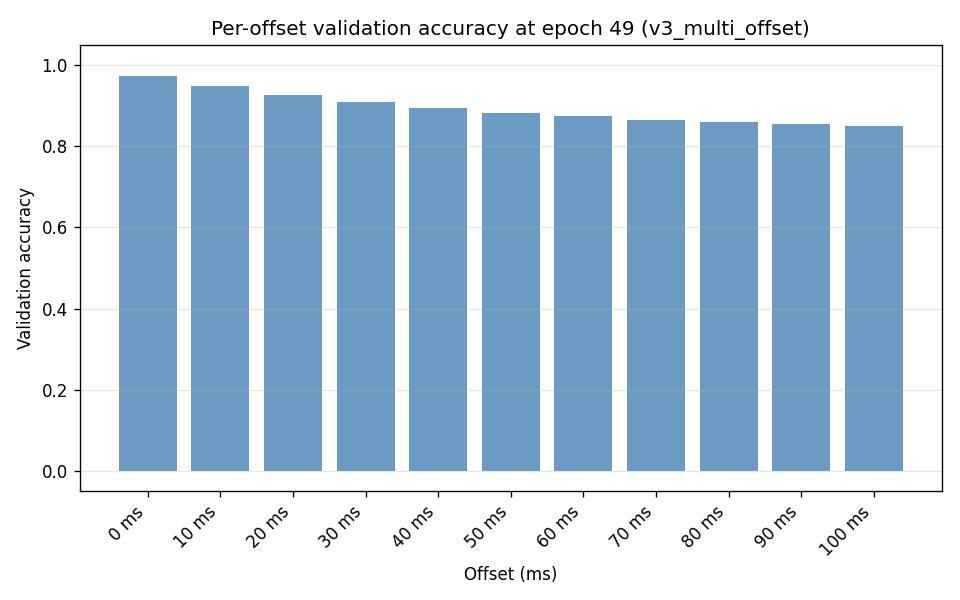
Per-offset validation accuracy (last epoch):
val_acc_offset_ms_0= 0.972,val_acc_offset_ms_10= 0.948,val_acc_offset_ms_20= 0.927, …,val_acc_offset_ms_100= 0.849. Offset 0 (current tick) is strongest; accuracy decreases for farther offsets as expected.
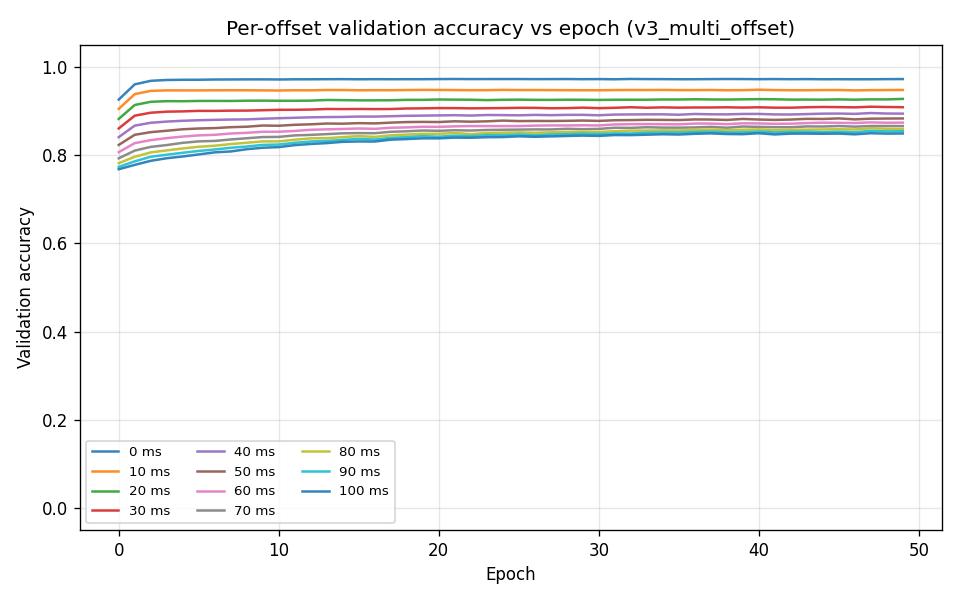
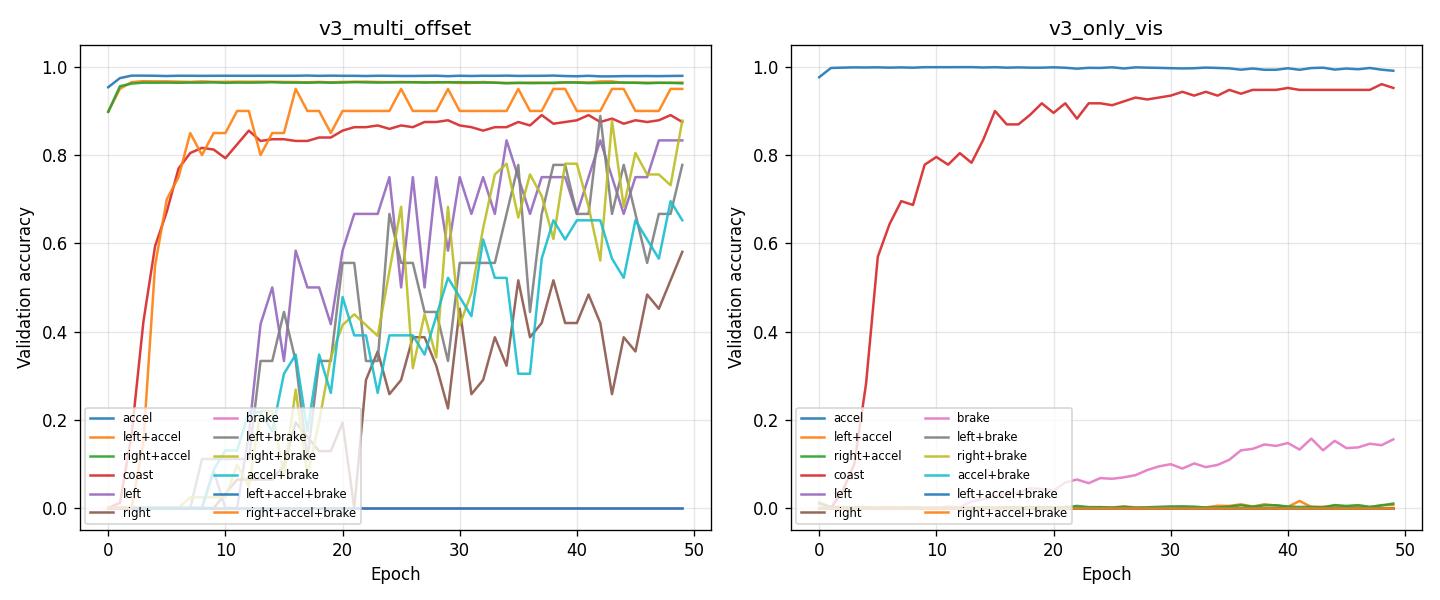
Per-action validation accuracy: accel 0.98, left+accel 0.96, right+accel 0.96, coast 0.88; left 0.83, right 0.58, brake 0, left+brake 0.78, right+brake 0.88, accel+brake 0.65, left+accel+brake 0, right+accel+brake 0.95. brake and left+accel+brake show 0 — rare classes (see class distribution below).
main_actions_val_acc (best epoch): 0.789 (vs v3 0.22, v3_only_vis 0.33).
Class distribution (train, offset 0, from cache/v1)
The dataset is highly imbalanced:
accel: 58.76%
left+accel: 19.15%
right+accel: 21.14%
coast: 0.35%
brake: 0.27%
left+accel+brake: 0.10%
right+accel+brake: 0.09%
left, right, left+brake, right+brake, accel+brake: < 0.05% each
The three main actions (accel, left+accel, right+accel) account for ~99% of samples. Rare actions (brake, left+accel+brake, etc.) have few or no validation samples in some track splits, which explains val_acc_class = 0 for brake and left+accel+brake. The high overall val_acc (0.89) reflects good prediction of the dominant classes.
Comparison with v3 and v3_only_vis
Metric |
v3_multi_offset |
v3 |
v3_only_vis |
|---|---|---|---|
train_acc (last) |
0.900 |
0.586 |
0.592 |
val_acc (last) |
0.894 |
0.607 |
0.607 |
main_actions_val_acc (best) |
0.789 |
0.218 |
0.325 |
Best epoch by val_loss |
49 |
8 |
42 |
Overfitting |
No |
N/A (collapsed) |
No |
Stability |
Stable |
Unstable |
Stable |
Conclusion: v3_multi_offset stabilizes full IQN + floats on the img dataset. Multi-offset training avoids the collapse seen in v3 and achieves much higher val_acc and main_actions_val_acc than v3_only_vis. No overfitting; best epoch is the last (49). Class distribution is imbalanced; val_acc_class = 0 for rare classes (brake, left+accel+brake) reflects few or no val samples, not model failure.
How to run
.\.venv\Scripts\python.exe scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v3_multi_offset.yaml
Reproduce (includes –plot to regenerate graphs)
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3_multi_offset output/ptretrain/bc/v3_only_vis --interval 5 --plot --output-dir docs/source/_static
Experiment: Single-head current tick vs multi-offset (v3_current_tick vs v3_multi_offset)
Overview: This experiment compares single-head BC (current tick only) with multi-offset BC (11 heads at 0–100 ms) on the img 100 FPS dataset. Both use use_full_iqn: true, use_floats: true, same encoder init (vis v2), same hyperparameters (50 epochs, batch 4096, lr 0.0001). The only structural difference is the number of action heads.
Configs:
v3_current_tick (
config_files/pretrain/bc/pretrain_config_bc_v3_current_tick.yaml):run_name: v3_current_tick,preprocess_cache_dir: cache/v1.1, nobc_time_offsets_ms→ single head (offset 0 only).v3_multi_offset (
config_files/pretrain/bc/pretrain_config_bc_v3_multi_offset.yaml):run_name: v3_multi_offset,preprocess_cache_dir: cache/v1,bc_time_offsets_ms: [0, 10, 20, ..., 100],bc_offset_weights: [5, 4, 3, 2, 1, 1, ...]→ 11 heads.
Caveat: Different cache dirs (v1.1 vs v1); both runs have the same n_train (606,966) and n_val (66,352), so the source data is likely equivalent. Loss scale differs: v3_current_tick loss ≈ 0.10 (single cross-entropy); v3_multi_offset loss ≈ 4.4 (weighted sum of 11 cross-entropies). Loss values are not directly comparable.
Key findings
Offset-0 (current tick) accuracy: v3_multi_offset val_acc_offset_ms_0 = 0.9723 vs v3_current_tick val_acc = 0.9732 — essentially identical. The multi-offset head at offset 0 predicts as well as the single-head model.
main_actions_val_acc (best epoch): v3_current_tick 0.7926, v3_multi_offset 0.7886 — nearly the same.
Per-action validation accuracy (epoch 49): Very similar. v3_current_tick is slightly better on coast (0.8945 vs 0.8750); v3_multi_offset is slightly better on left (0.83 vs 0.75), right (0.58 vs 0.39). Main actions (accel, left+accel, right+accel, right+accel+brake) are within 0–2 pp.
Training curves: v3_current_tick converges faster (val_acc 0.97 by epoch 5); v3_multi_offset plateaus around 0.89. Both are stable; no collapse.
Multi-offset benefit: v3_multi_offset additionally predicts actions at +10 ms through +100 ms (val_acc_offset_ms_100 ≈ 0.85). If you need only current-tick prediction, single-head (v3_current_tick) is simpler and matches multi-offset at offset 0. Use multi-offset when you want predictions at multiple future offsets or when multi-task regularization helps stability (as with v3 vs v3_multi_offset in the full-IQN case).
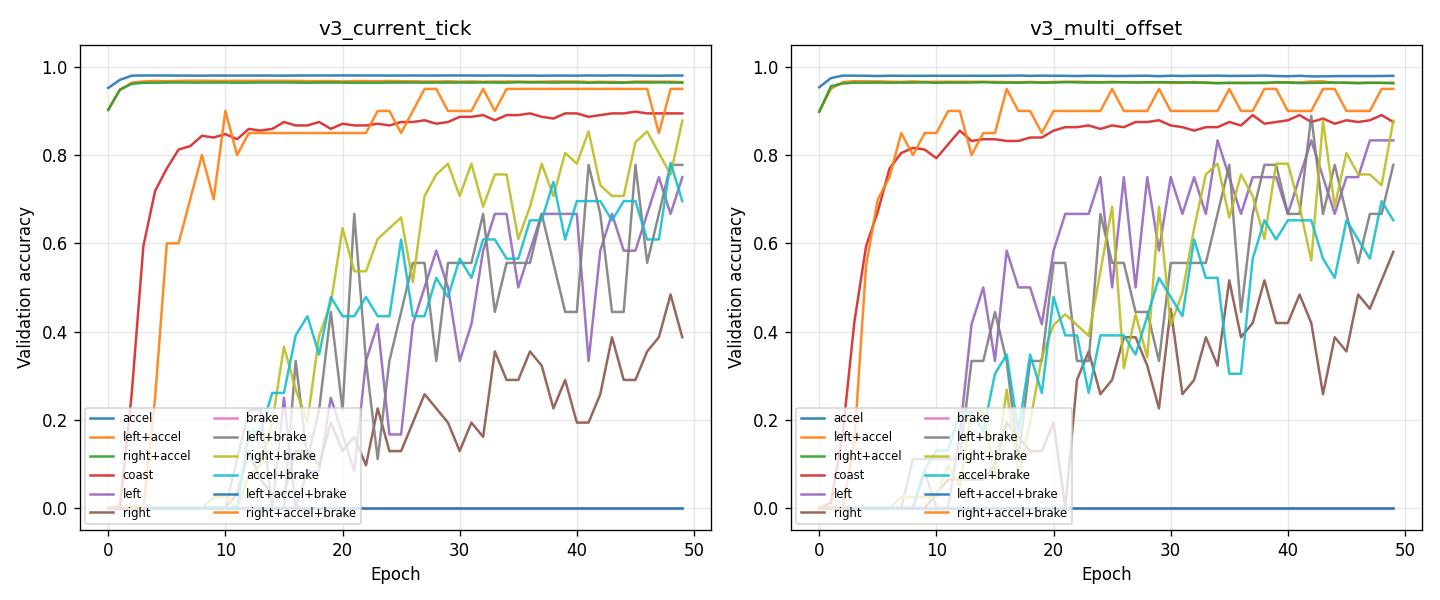
Run analysis
v3_current_tick: Config
pretrain_config_bc_v3_current_tick.yaml. 50 epochs; val_acc 0.973, val_loss 0.102; best epoch 48; main_actions_val_acc 0.793. CSV:output/ptretrain/bc/v3_current_tick/csv/metrics.csv.v3_multi_offset: Config
pretrain_config_bc_v3_multi_offset.yaml. 50 epochs; val_acc 0.894 (aggregate over 11 heads); val_acc_offset_ms_0 0.972; best epoch 49; main_actions_val_acc 0.789. CSV:output/ptretrain/bc/v3_multi_offset/csv/metrics.csv.
Conclusion: For current-tick prediction only, single-head (v3_current_tick) and multi-offset (v3_multi_offset, offset-0 head) achieve the same accuracy (~97%). Multi-offset adds predictions at +10 ms through +100 ms at the cost of higher loss scale and slightly more compute. Use v3_current_tick when you need only MDP-aligned action; use v3_multi_offset when you want multi-offset predictions or multi-task regularization.
Reproduce
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3_current_tick output/ptretrain/bc/v3_multi_offset --interval 5 --plot --output-dir docs/source/_static
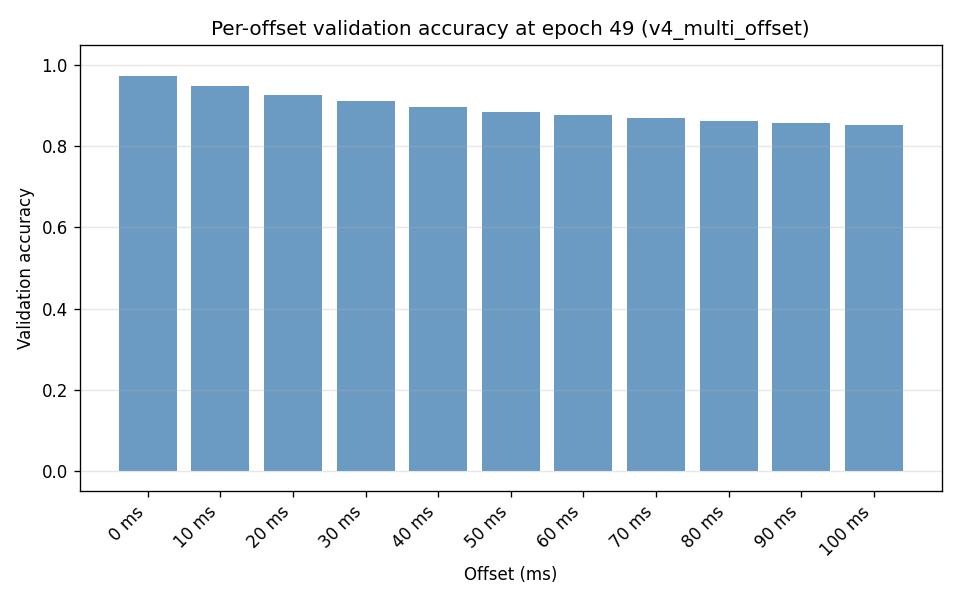
Experiment: Full IQN BC with V_head trained (v4_multi_offset vs v3_multi_offset)
Overview: The only difference between v3 and v4 is that in v4 we also train V_head. In v3 the BC forward returns only A_heads logits, so V_head is never in the loss path and stays at init. In v4 the forward uses the dueling formula Q = V + A - A.mean(dim=-1) (same as in RL), so V_head receives gradients and is trained together with A_heads. Same data, same cache, same config and hyperparameters — only the forward (and thus what gets trained) changes.
Configuration: Same as v3_multi_offset except run_name: v4_multi_offset. Config: config_files/pretrain/bc/pretrain_config_bc_v4_multi_offset.yaml. Data, cache, multi-offset setup (11 heads, same weights), and all training hyperparameters are unchanged.
Run
python scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v4_multi_offset.yaml
Analysis: Compare pretrain metrics (train/val loss, per-offset accuracy) and downstream RL (e.g. A01 best time, finish rate) with v3:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3_multi_offset output/ptretrain/bc/v4_multi_offset --interval 5
Artifacts: Both v3 and v4 produce iqn_bc.pt with img_head, float_feature_extractor, iqn_fc, V_head, and A_head (offset 0). In v4, V_head is trained; in v3 it is not. RL injection (inject_bc_heads_into_iqn) copies all matching keys, so the trained V_head from v4 is loaded into the RL network when using pretrain_bc_heads_path pointing at the v4 run directory.
Run output: v4 run directory is at output/ptretrain/bc/v4_multi_offset (encoder.pt, iqn_bc.pt, pretrain_meta.json, csv/, checkpoints/).
Results (from ``analyze_pretrain_bc.py output/ptretrain/bc/v3_multi_offset output/ptretrain/bc/v4_multi_offset –interval 5``):
Summary (50 epochs): v3 — train_acc 0.900, val_acc 0.894, train_loss 4.15, val_loss 4.41. v4 — train_acc 0.900, val_acc 0.896, train_loss 4.13, val_loss 4.38. v4 has slightly lower val_loss and slightly higher val_acc.
Best epoch by val_loss: Both best at epoch 49. v3: val_loss 4.4099, val_acc 0.8940, main_actions_val_acc 0.7886. v4: val_loss 4.3793, val_acc 0.8962, main_actions_val_acc 0.7908. v4 is marginally better on all three.
Per-offset validation accuracy (last epoch): v4 is better or equal at every offset: offset 0 — v3 0.9723, v4 0.9721 (tie); offset 10 — v3 0.9476, v4 0.9479; offset 100 — v3 0.8490, v4 0.8529. Farther offsets (60–100 ms) gain ~0.3–0.4 pp in v4.
Per-action (epoch 49): Main actions (accel, left+accel, right+accel, coast, right+accel+brake) are similar or slightly better in v4; some rare actions (left, right, left+brake, right+brake) have fewer val samples and vary. main_actions_val_acc is higher in v4 (0.7908 vs 0.7886).
Conclusion: Training V_head via the dueling formula in BC (v4) gives slightly better validation loss, overall val_acc, main_actions_val_acc, and per-offset accuracy than v3 (A_heads only). The gain is small but consistent. Use v4_multi_offset for RL injection when you want both V and A heads pretrained; downstream RL comparison (e.g. A01 best time, finish rate) can confirm whether the trained V_head helps in practice.
General takeaway: With the only change being “we now train V_head too”, v4 improves pretrain metrics across the board. So jointly training V_head in BC is beneficial and does not hurt; prefer v4 for full IQN pretrain.
Experiment: Multi-offset BC fused heads (v5_multi_offset vs v4_multi_offset)
Overview: This experiment tests a new multi-offset BC variant where we (1) shorten the offset horizon to bc_time_offsets_ms: [0, 10, 20, 30, 40] (5 heads) instead of v4’s 11 heads up to 100 ms, and (2) switch the multi-offset architecture to bc_multi_offset_mode: fused (shared A_head producing N*n_actions outputs). The run keeps the same overall BC target semantics (bc_target: current_tick) and uses IQN-style image normalization and the full IQN model (use_full_iqn: true).
Config: config_files/pretrain/bc/pretrain_config_bc_v5_multi_offset.yaml (run_name: v5_multi_offset). Key overrides:
bc_time_offsets_ms: [0, 10, 20, 30, 40]bc_offset_weights: [1.0, 1.0, 1.0, 1.0, 1.0]bc_multi_offset_mode: fusedfull_iqn_random_tau: true
Run:
python scripts/pretrain_bc.py --config config_files/pretrain/bc/pretrain_config_bc_v5_multi_offset.yaml
Analysis: Compare v5 vs v4 (both by epoch) using Lightning CSV:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v5_multi_offset output/ptretrain/bc/v4_multi_offset --interval 5
Results (by epoch; both runs trained 50 epochs):
Best epoch by val_loss: both are best at epoch 49.
Overall accuracy:
v5_multi_offsetimproves over v4:val_acc=0.9359vs0.8962.Main actions validation accuracy (mean over accel, left+accel, right+accel, coast, left+accel+brake, right+accel+brake):
v5_multi_offsetmain_actions_val_acc=0.7858vsv4_multi_offset0.7908(very close).Loss note:
val_lossscales with the number of offset heads and the loss weighting, so it is not directly comparable across v5 (5 heads) vs v4 (11 heads). Useval_accand per-offset/per-action accuracies for comparison.
Per-offset validation accuracy (final epoch):
v5_multi_offset (offsets 0..40 ms): 0 ms 0.9716; 10 ms 0.9496; 20 ms 0.9320; 30 ms 0.9186; 40 ms 0.9077.
v4_multi_offset (common offsets 0..40 ms): 0 ms 0.9721; 10 ms 0.9479; 20 ms 0.9268; 30 ms 0.9106; 40 ms 0.8964 (v4 also continues to 100 ms with decreasing accuracy).
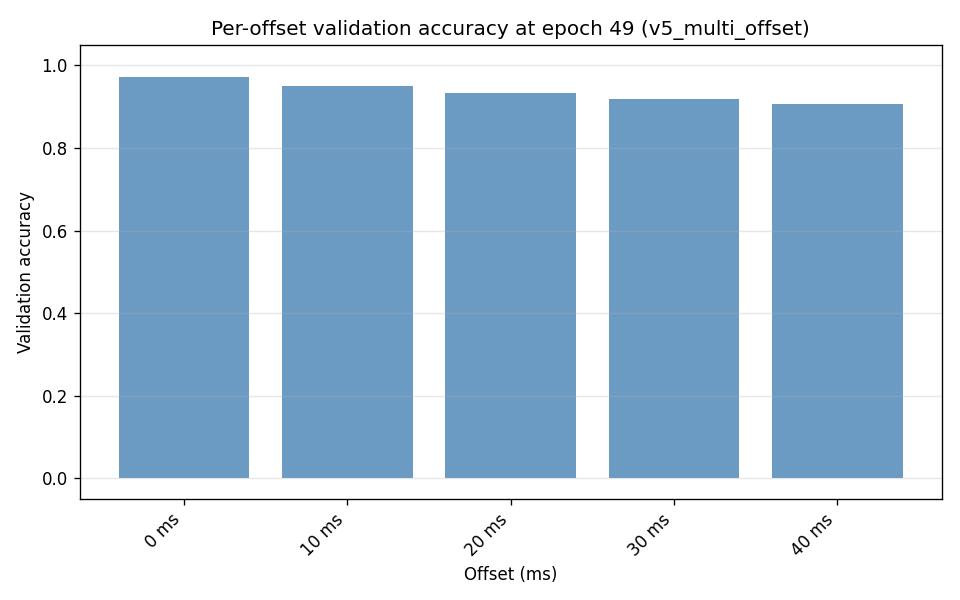
Per-action validation accuracy (final epoch, action names):
v5 matches v4 on dominant actions like
accel(0.9796 vs 0.9786) andleft+accel/right+accel(both around 0.962-0.963).v4 is better on
coast(0.8867 vs 0.8594) andright+brake(0.7805 vs 0.3659).v5 is better on
left(0.8333 vs 0.6667),left+brake(0.5556 vs 0.3333), andaccel+brake(0.6522 vs 0.6087).
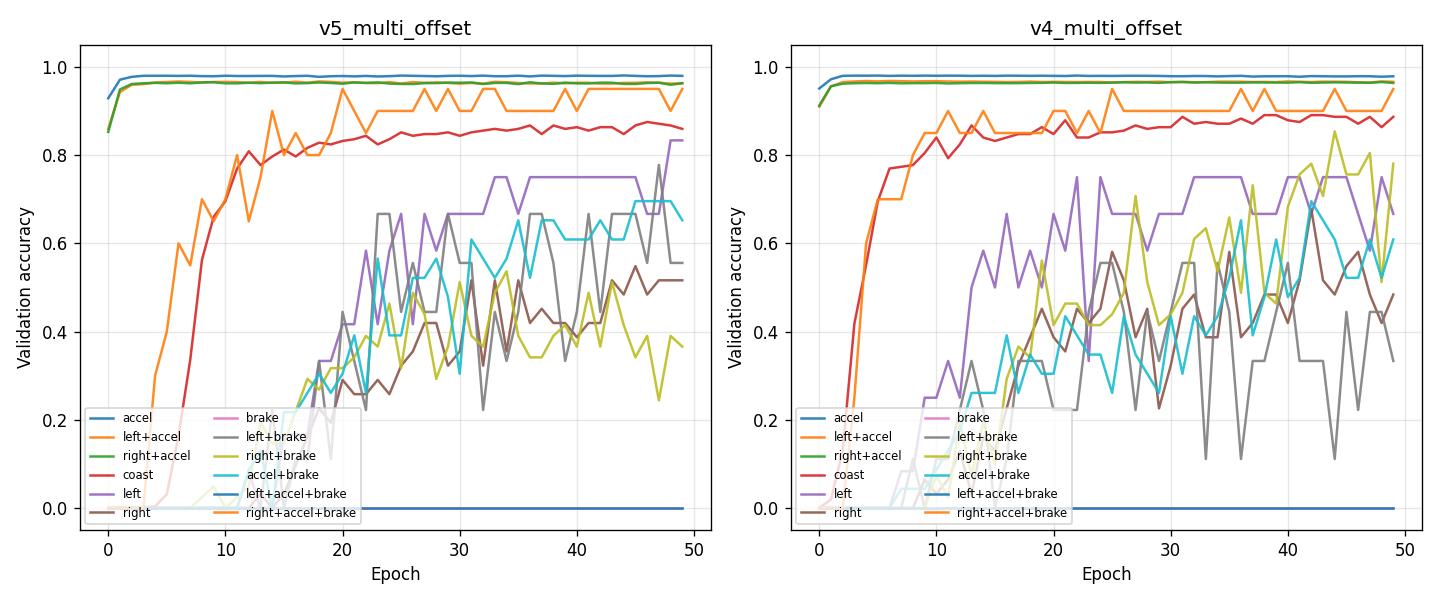
Conclusion: With fewer offset heads (0-40 ms) and the fused multi-offset architecture, v5_multi_offset achieves a noticeably higher overall val_acc while keeping main_actions_val_acc essentially unchanged vs v4. It trades some performance on coast and right+brake for gains on left / left+brake / accel+brake.
Configuration Changes (v2 chain)
Visual pretrain:
config_files/pretrain/vis/pretrain_config_vis_iqn.yaml— run_name: v2, image_normalization: “iqn”, preprocess_cache_dir: cache/v0; other fields as inconfig_files/pretrain/vis/pretrain_config.yaml(early_stopping: false).BC pretrain:
config_files/pretrain/bc/pretrain_config_bc_v2.yaml— run_name: v2, encoder_init_path:output/ptretrain/vis/v2/encoder.pt, image_normalization: “iqn”, preprocess_cache_dir: cache/v0; same training hyperparameters as main BC config.
Hardware (v2 chain)
Same as other pretrain runs (single GPU, Windows).
Conclusions (v2 chain)
Level 0 v2: Training the visual backbone with IQN normalization and cache v0 yields a valid encoder (val_loss 0.207 at 50 epochs). Ready for BC v2.
BC v2 vs v1.2 — action prediction accuracy: v1.2 and v2 are very close on val_loss (0.948–0.949) and overall val_acc (0.616–0.618). At best epoch by val_loss (epoch 38), v1.2 has higher main_actions_val_acc (0.517 vs 0.507), so v1.2 is marginally better for overall action prediction accuracy. v2 is clearly better for coast (0.64 vs 0.45 at epoch 49). Recommendation: For best aggregate action accuracy, use v1.2 (BC with IQN norm, backbone from vis/v1). For better coast prediction, use v2 (full IQN-aligned chain). Full alignment (vis+BC both with IQN norm) does not improve overall or main-actions accuracy over v1.2 in this comparison.
Recommendations (v2 chain)
For best action prediction accuracy (overall and main actions): use v1.2 (BC with
image_normalization: "iqn"and encoder from vis/v1). For better coast prediction, v2 is preferable.Reproduce comparison:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1.2 output/ptretrain/bc/v2 --interval 5.
Configuration Changes
BC pretrain (config_files/pretrain/bc/pretrain_config_bc.yaml):
v1: early_stopping enabled (or epochs capped at 25); lr as in config (e.g. 0.0005).
v1.1: early_stopping: false, lr: 0.0005, epochs: 50; image_normalization: default (
"01"= [0,1]).v1.2: Same as v1.1 except image_normalization: “iqn” (input
(x - 0.5) / 0.5on [0,1] cache).
Other settings shared: encoder_init_path: output/ptretrain/vis/v1/encoder.pt, bc_mode: backbone, n_actions: 12, batch_size: 4096, val_fraction: 0.1.
Full IQN-aligned chain (v2):
Visual pretrain:
config_files/pretrain/vis/pretrain_config_vis_iqn.yaml— run_name: v2, image_normalization: “iqn”. Same schema asconfig_files/pretrain/vis/pretrain_config.yaml.BC pretrain:
config_files/pretrain/bc/pretrain_config_bc_v2.yaml— run_name: v2, encoder_init_path:output/ptretrain/vis/v2/encoder.pt, image_normalization: “iqn”.
Hardware
Same as other pretrain/RL runs (single GPU, Windows).
Conclusions
Training length: ~20–25 epochs is enough; val_loss and val_acc do not improve after that and val_loss increases by 50 epochs (overfitting).
Early stopping: Recommended. Use val_loss with patience 5–10 so runs stop around 20–25 epochs and avoid overfitting.
Image normalization (v1.1 vs v1.2): IQN-style normalization helps. With image_normalization: “iqn” (v1.2), validation loss is ~15% lower (0.949 vs 1.119 at 50 epochs) and best-epoch val_loss and main_actions_val_acc are better (0.941 and 0.52 vs 0.994 and 0.42). Overall val_acc at the last epoch is similar or slightly lower; the gain is in generalization (loss). Both runs use a backbone pretrained without IQN normalization; using IQN normalization at BC time still improves results. Use ``image_normalization: “iqn”`` for BC when the encoder is intended for IQN transfer.
Full IQN-aligned chain (v2): Compared with analyze_pretrain_bc.py v1.2 v2. For action prediction accuracy: v1.2 is marginally better (higher overall val_acc and main_actions_val_acc at best epoch 38). v2 is better for coast (0.64 vs 0.45). Val_loss is tied. Use v1.2 for best aggregate action accuracy; use v2 if coast prediction matters more. See “Experiment: Full IQN-aligned chain” subsection for full metrics.
Three-way (v1.1 vs v1.2 vs v2): v1.1 has highest overall val_acc at epoch 49 (0.625) but worst val_loss (1.12) and lowest main_actions_val_acc at best epoch (0.42). v1.2 has best main_actions_val_acc at best epoch (0.517) and best val_loss. v2 has best coast (0.64). So: for generalization and main-actions accuracy prefer v1.2; for raw end val_acc v1.1 is highest (with more overfitting); for coast prefer v2.
Per-action metrics: Report and compare per-action accuracy by name (accel, left+accel, right+accel, coast, left+accel+brake, right+accel+brake). Rare actions (left, right, brake, left+brake, right+brake, accel+brake) have ~0 val samples; their val_acc_class_* are 0 or negligible.
BC target (v2 vs v2_next_tick): bc_target: next_tick gives lower action prediction accuracy than current_tick: overall val_acc ~0.55 vs 0.62, main_actions_val_acc at best epoch 0.32 vs 0.51; coast drops to 0 with next_tick. Prefer current_tick for best accuracy unless the downstream task requires next-tick prediction.
n_stack (v2_next_tick vs v2_next_tick_stack3): n_stack=3 uses three consecutive frames per sample (temporal context) but significantly increases RAM usage (cache ~3× larger, batch 3× more pixel data). The stack3 config uses
cache_load_in_ram: falseandworkers: 1to avoid OOM. Comparison (documented v2_next_tick n_stack=1 vs current overwritten run = n_stack=3): n_stack=3 gives slightly better val_loss (1.074 vs 1.116), best-epoch main_actions_val_acc (0.327 vs 0.315), and accel accuracy (0.744 vs 0.702); some actions are slightly worse. The gain is modest; whether it justifies the memory cost is a trade-off.Multi-offset Linear vs A_head (v2_multi_offset vs v2_multi_offset_ahead): v2_multi_offset (Linear heads) gives better validation (val_acc 0.612, per-offset ~0.59–0.62, best epoch 49). v2_multi_offset_ahead (MLP A_head) overfits: best epoch by val_loss = 14, then val_acc drops to 0.55 and val_loss rises to 2.88 by epoch 49. Use v2_multi_offset for best multi-offset accuracy; if using v2_multi_offset_ahead for RL merge, enable early stopping or use checkpoint at best epoch ~14 (see “Experiment: vis backbone + a_head only”). v2_multi_offset_ahead_tuned (lr 0.0002, weight_decay 0.01, early_stopping) reaches val_acc 0.591 and per-offset ~0.59–0.60, stops at ~epoch 26; recommended for RL merge when you need A_head.
Full IQN + floats vs visual-only (v3 vs v3_only_vis) on img 100 FPS: v3_only_vis is stable; v3 (use_full_iqn, without floats) exhibits training instability and mode collapse. v3_multi_offset (full IQN + floats, multi-offset) is stable and achieves val_acc 0.89, main_actions_val_acc 0.79; no overfitting. Prefer v3_multi_offset when full IQN + floats is needed; otherwise v3_only_vis for visual-only.
Single-head vs multi-offset (v3_current_tick vs v3_multi_offset): For current-tick prediction only, both achieve the same offset-0 accuracy (~97%). Use v3_current_tick when you need only MDP-aligned action; use v3_multi_offset when you want predictions at multiple future offsets or multi-task regularization.
Full IQN with V_head trained (v4_multi_offset vs v3_multi_offset): v4 uses the dueling formula in the BC forward (Q = V + A - A.mean) so V_head is trained; v3 only trained A_heads. Pretrain metrics: v4 has slightly lower val_loss (4.38 vs 4.41), higher val_acc (0.896 vs 0.894), and higher main_actions_val_acc (0.791 vs 0.789) at best epoch 49; per-offset accuracy is better or equal in v4 at all offsets. Use v4_multi_offset for RL injection when you want both V and A pretrained; downstream RL (e.g. A01 best time, finish rate) can confirm whether the trained V_head helps in practice.
Recommendations
Use early stopping on val_loss (patience 5–10) for BC pretrain.
Do not train beyond ~25 epochs unless you have evidence of underfitting (e.g. val_loss still decreasing).
Use image_normalization: “iqn” for BC pretrain when the encoder will be loaded into IQN; it reduces val_loss and improves best-epoch metrics even when the visual backbone was pretrained without IQN normalization.
Best for action prediction accuracy: Use v1.2 (BC with IQN norm, encoder from vis/v1) for best main_actions_val_acc at best epoch and best val_loss; use v2 if coast prediction is the priority. v1.1 has the highest overall val_acc at epoch 49 (0.625) but the worst val_loss (overfitting).
n_stack: Use n_stack=1 unless you have evidence that n_stack=3 improves accuracy enough to justify the higher RAM usage (and possibly
cache_load_in_ram: false, fewer workers). Run both with distinct run names and compare withanalyze_pretrain_bc.py.Multi-offset (v2_multi_offset vs v2_multi_offset_ahead): For best multi-offset validation accuracy use v2_multi_offset (Linear heads). For RL merge of vis + A_head only use v2_multi_offset_ahead_tuned (lr 0.0002, weight_decay 0.01, early_stopping — val_acc 0.591, stops ~epoch 26) or v2_multi_offset_ahead_reg (lr 0.0001, weight_decay 0.02, no early stop, 50 epochs — val_acc 0.592, best epoch 35) or v2_multi_offset_ahead_dropout (reg + dropout 0.2 — val_acc 0.595, val_loss 1.989, best A_head) or v2_multi_offset_ahead_dropout_inner (dropout 0.2 + action_head_dropout 0.1 — val_acc 0.597, val_loss 1.971, best A_head). Untuned v2_multi_offset_ahead overfits; if used, enable early stopping or checkpoint at epoch ~14.
Full IQN + floats vs visual-only (v3 vs v3_only_vis) on img 100 FPS: v3_only_vis (visual backbone only) is stable. v3 (full IQN without floats) suffers from training instability and mode collapse. v3_multi_offset (full IQN + floats, multi-offset) is stable and achieves val_acc 0.89, main_actions_val_acc 0.79, no overfitting. Use v3_multi_offset when full IQN + floats is needed; v3_only_vis for visual-only.
Single-head vs multi-offset (v3_current_tick vs v3_multi_offset): For current-tick prediction only, both achieve the same offset-0 accuracy (~97%). Use v3_current_tick when you need only MDP-aligned action; v3_multi_offset when you want multi-offset predictions.
Full IQN with V_head trained (v4_multi_offset): Same config as v3_multi_offset but the model forward uses the dueling formula so V_head receives gradients. v4 gives slightly better pretrain metrics (val_loss 4.38 vs 4.41, val_acc 0.896 vs 0.894, main_actions_val_acc 0.791 vs 0.789). Use v4_multi_offset when you want the full IQN (including V_head) pretrained for RL injection; compare downstream RL (e.g. A01) to confirm benefit.
For analysis, use scripts/analyze_pretrain_bc.py with run dirs or
--base-dir output/ptretrain/bc v1 v1.1(orv1.1 v1.2for normalization comparison) to get tables by epoch, combined analysis (best epoch by val_loss + main_actions_val_acc), and per-action accuracy with human-readable names (accel, left+accel, right+accel, etc.).To generate the per-action accuracy plot:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1 output/ptretrain/bc/v1.1 --plot --output-dir docs/source/_static(savesexp_pretrain_bc_v1_v1.1_per_action_accuracy.jpg). Filenames are derived from run names; use--prefix <name>to override.
Analysis tools
BC pretrain comparison:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1 output/ptretrain/bc/v1.1 --interval 5Normalization (v1.1 vs v1.2):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1.1 output/ptretrain/bc/v1.2 --interval 5Full IQN-aligned chain (v1.2 vs v2):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1.2 output/ptretrain/bc/v2 --interval 5BC target current_tick vs next_tick (v2 vs v2_next_tick):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v2 output/ptretrain/bc/v2_next_tick --interval 5Multi-offset Linear vs A_head (incl. dropout):
.\.venv\Scripts\python.exe scripts/analyze_pretrain_bc.py output/ptretrain/bc/v2_multi_offset output/ptretrain/bc/v2_multi_offset_ahead output/ptretrain/bc/v2_multi_offset_ahead_tuned output/ptretrain/bc/v2_multi_offset_ahead_reg output/ptretrain/bc/v2_multi_offset_ahead_dropout output/ptretrain/bc/v2_multi_offset_ahead_dropout_inner --interval 5n_stack 1 vs 3 (v2_next_tick vs v2_next_tick_stack3): Original v2_next_tick (n_stack=1) was overwritten; comparison is in the doc (documented n_stack=1 vs current dir = n_stack=3). To print metrics for the current run only:
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v2_next_tick --interval 5. If you re-run both with distinct run names, use the two-dir command to compare.Three-way (v1.1 vs v1.2 vs v2):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v1.1 output/ptretrain/bc/v1.2 output/ptretrain/bc/v2 --interval 5Full IQN + floats vs visual-only (v3 vs v3_only_vis):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3 output/ptretrain/bc/v3_only_vis --interval 5Multi-offset on img (v3_multi_offset vs v3_only_vis):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3_multi_offset output/ptretrain/bc/v3_only_vis --interval 5 --plot --output-dir docs/source/_static(--plotgenerates per-action vs epoch and per-offset graphs)Single-head vs multi-offset (v3_current_tick vs v3_multi_offset):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3_current_tick output/ptretrain/bc/v3_multi_offset --interval 5 --plot --output-dir docs/source/_staticFull IQN with V_head trained (v4 vs v3_multi_offset):
python scripts/analyze_pretrain_bc.py output/ptretrain/bc/v3_multi_offset output/ptretrain/bc/v4_multi_offset --interval 5With explicit CSV:
python scripts/analyze_pretrain_bc.py --csv output/ptretrain/bc/v1/csv/metrics.csv output/ptretrain/bc/v1.1/csv/metrics.csvWith base dir:
python scripts/analyze_pretrain_bc.py --base-dir output/ptretrain/bc v1 v1.1